Building a Production-Grade Trading System with Claude Code
9,437 commits. 1,419 issues. 5 months of tracked code. Half of it was fixing things I broke.
That’s the short version. The long version starts with a hacky Google spreadsheet, goes through 3 years of trading study, and ends with a production-grade autonomous trading system built with Claude Code. The 5 months is just the GitHub-tracked phase. The full journey (including about 9 months of intensive building at 12-15 hours a day, 7 days a week) is longer. Let me explain.
The Spreadsheet
It started with a Google Sheet. I’d spent about 3 years studying trading, technical analysis, and risk management before writing a single line of code. Manual trading, reading, paper trading, losing money, learning why I lost money. The usual.
By November 2024 I left my corporate job (8 years at Canonical, the Ubuntu people). Enough was enough. I needed a change of scenery. I wanted to free up more time, so I invested the time to automate the trading. When I finally sat down to build it, I built the MVP in Google Apps Script. 24 modules. A Google Sheet talking to Interactive Brokers through an ngrok tunnel via a FastAPI bridge. Sounds mental, and it was. The architecture looked like this: Google Sheets to GAS to ngrok tunnel to FastAPI to IBKR TWS. Every time the tunnel died, the system died. The Google Apps Script had a 6-minute execution limit (cheers, Google). I had to build an entire repair system just to keep the spreadsheet structure from breaking itself.
But it worked. Barely. Three take-profit strategies, one-click bracket orders, a background poller that synced positions every 5 minutes. 222 commits. I called it tradebook_GAS and it taught me everything I needed to know about what NOT to build next time.
That was the whole point of doing it on a spreadsheet first: figure out what data sets and calculations we actually need. Most of those spreadsheet columns carried over into database columns in the production system (we took what we needed, ditched what wasn’t useful). The pain of building tradebook_GAS wasn’t wasted. It was the blueprint for the tradebook side. But the production system went way beyond that: full automation, backtesting engine, signal detection, strategy management, real-time data streaming, order execution. The limitations of the spreadsheet (no backtesting, no automated scanning, ngrok dying at 3am) became the requirements list for everything else.
The Build
I started the intensive build phase in June 2025 with ChatGPT (free tier, then Plus). Built the tradebook_GAS MVP entirely on ChatGPT over about 3 months. Then in October 2025, I switched to Claude Code and started tracking everything in GitHub. That’s when things got properly serious.
The tech stack: Python, Rust, PostgreSQL, Redis, Interactive Brokers TWS API. React dashboard with TradingView charts. Systemd services on WSL2 Ubuntu. It’s a production-grade deployment running 8 strategies across 592 tickers with dual high-availability data services, circuit breakers, and a 4-phase startup order with CPU priority scheduling.
The Rust data service handles real-time market data from Finnhub WebSocket, streams it through Redis, and broadcasts via SSE. The Python controllers place and manage orders through IBKR. The dashboard is read-only (it never touches the broker directly, everything goes through Redis IPC queues to the controllers). That separation took three architecture rewrites to get right. The first version had the dashboard holding its own broker connection. The second had ephemeral connections that dropped trade IDs before the broker returned them. Third time lucky. Redis IPC queues. Dashboard dispatches commands, controllers execute them. Stateless frontend, stateful backend. Should have done it that way from the start (but that’s hindsight for you).
Alongside the system, I built a development workflow I call SST3 (public repo: SST3-AI-Harness). It’s a methodology for working with AI agents: subagents do the research and planning, the main agent writes the code with full context and accountability. I documented every failure as an anti-pattern. Started with 5 anti-patterns. Now there’s 16. Each one cites the specific issue where I first caught the problem. AP #16, for example, was born from me telling Claude: “you have a tendency to just fire and forget scripts, when what I need you to do is fire and monitor and ensure no problems.”
Every merge goes through a three-tier review gate (I call it Ralph Review). Haiku checks the surface. Sonnet checks the logic. Opus does the deep analysis. Fail any tier, fix it, restart from tier 1.
The Crisis
March 2026. I found negative AAPL positions in my paper trading account.
Negative. As in short. I don’t short stocks.
Root cause: my end-to-end tests were using AAPL as the default test ticker with hardcoded $1.00 entry prices. The test cleanup placed GTC sell orders that survived teardown. Those orphaned sell orders accumulated. When they filled against a zero position… shorts.
I audited all 174 E2E tests. Found them to be largely smoke tests. 25+ assertions that literally cannot fail (or True, >= 0). Signature mismatches in 3 files. The test suite was giving me green ticks while the system was creating phantom positions. Brilliant.
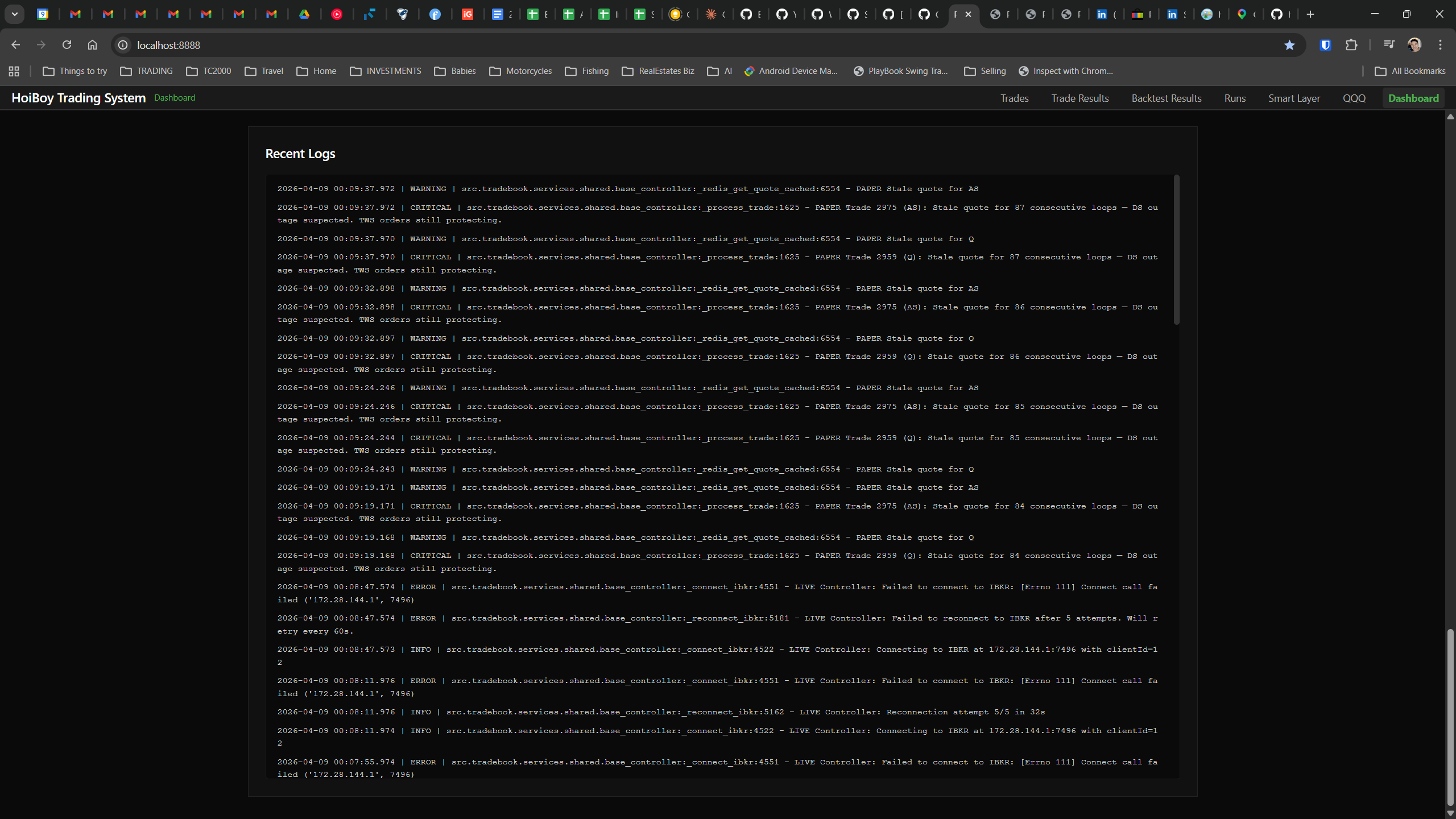
Here’s the ugly truth: 51.5% of all commits in this repo are fixes. Not features. Not optimisations. Fixes. Half of everything I built, I broke first. And I’m not talking about cosmetic stuff. I’m talking about a data service that silently dropped 50% of market sentiment data for 45 days because a chunk-splitting function only split one level deep. I’m talking about a row-factory bug that wrote NULL to every single order audit event since the code shipped. Production bugs. Real ones.
That’s what production actually looks like (anyone who tells you otherwise is selling something).
The Pivot
Issue #1338 was the turning point. Unified Order Flow Architecture. I replaced fragmented order paths with a single gateway, added trade-level locks, built a position authority that fails loud (no silent defaults, ever), and wired in a unified fill handler. Three deep audit rounds with 20 subagents. The architecture that finally made me sleep at night.
Before #1338, there were five different sources of position truth and two separate order surfaces. No trade-level lock meant a stop fill and a target fill could race each other concurrently. Nine production gaps that could produce short positions under race conditions. Nine. After #1338, one gateway, one authority, one fill handler. Every broker call logged to an audit trail. The emergency brake at 25% drawdown is non-overrideable… because I know myself.
The Dashboard
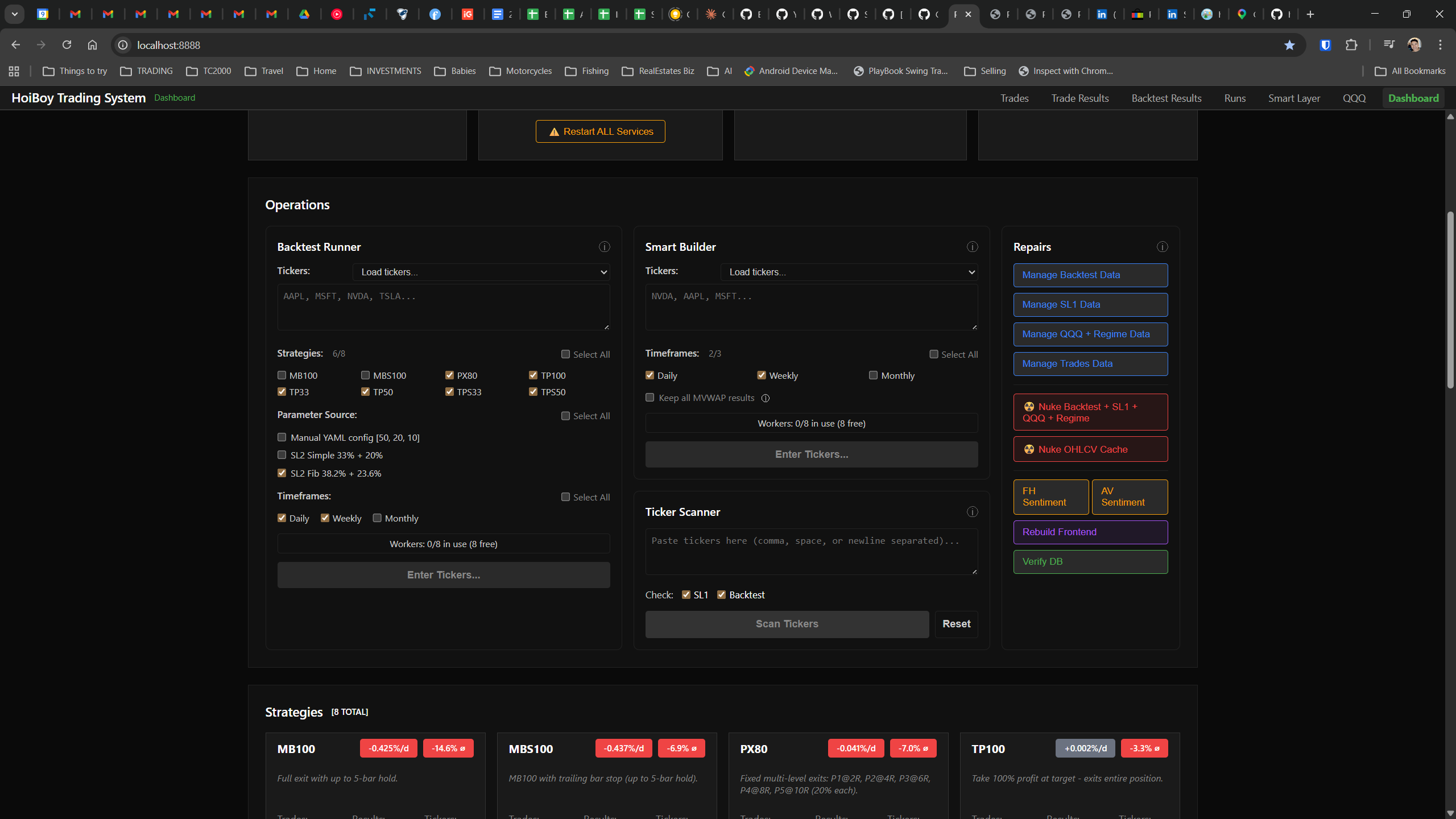
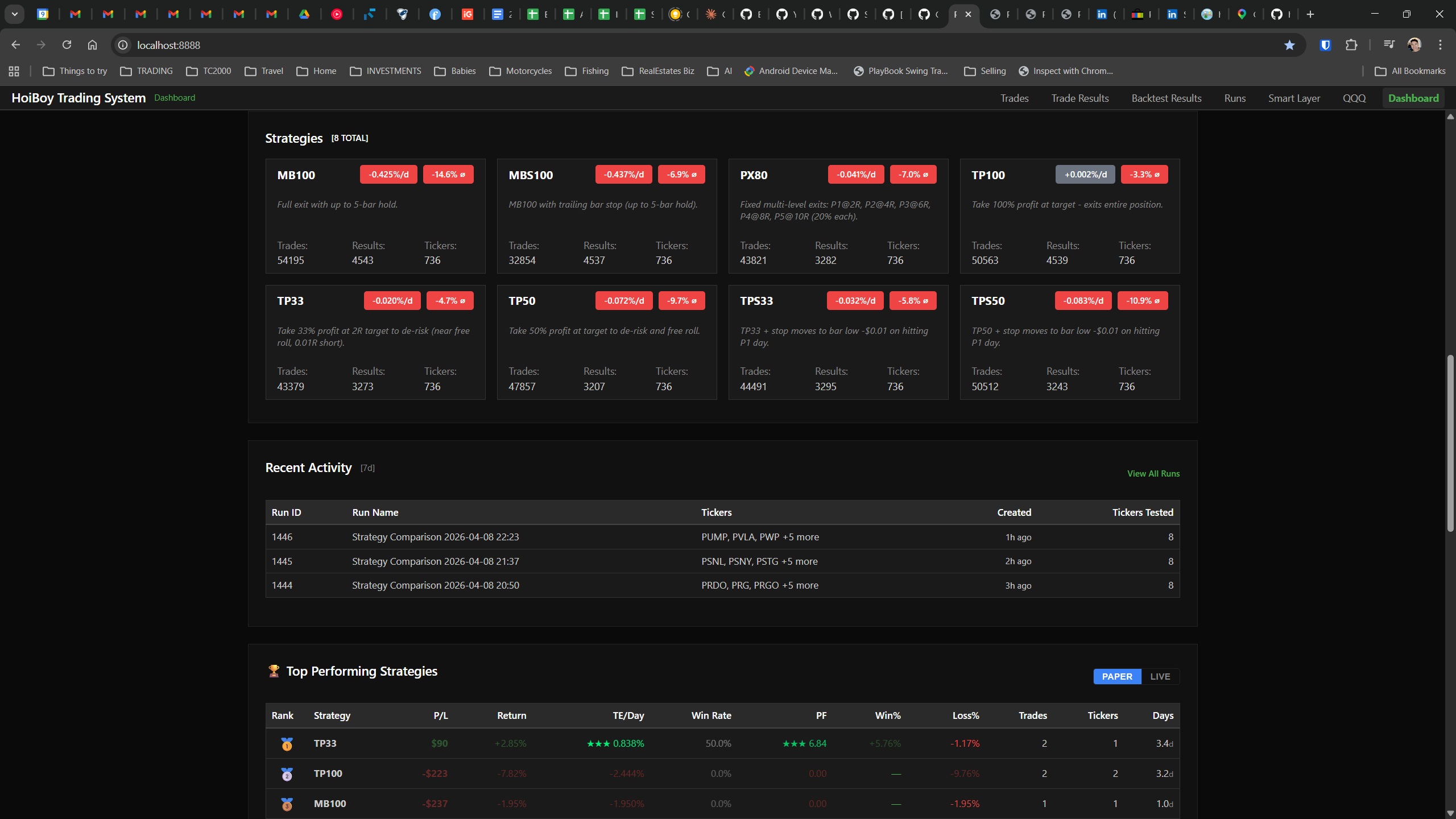
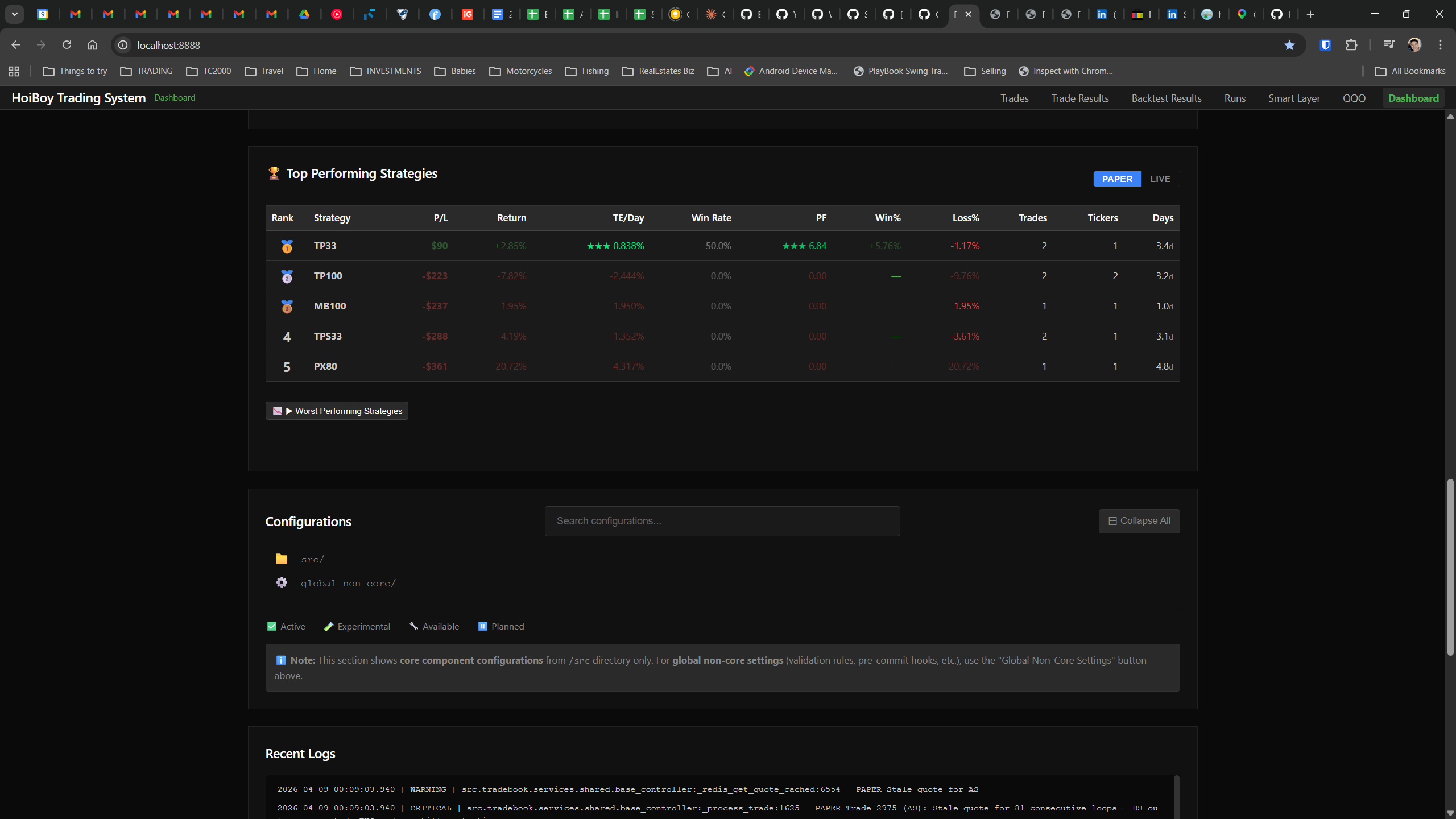
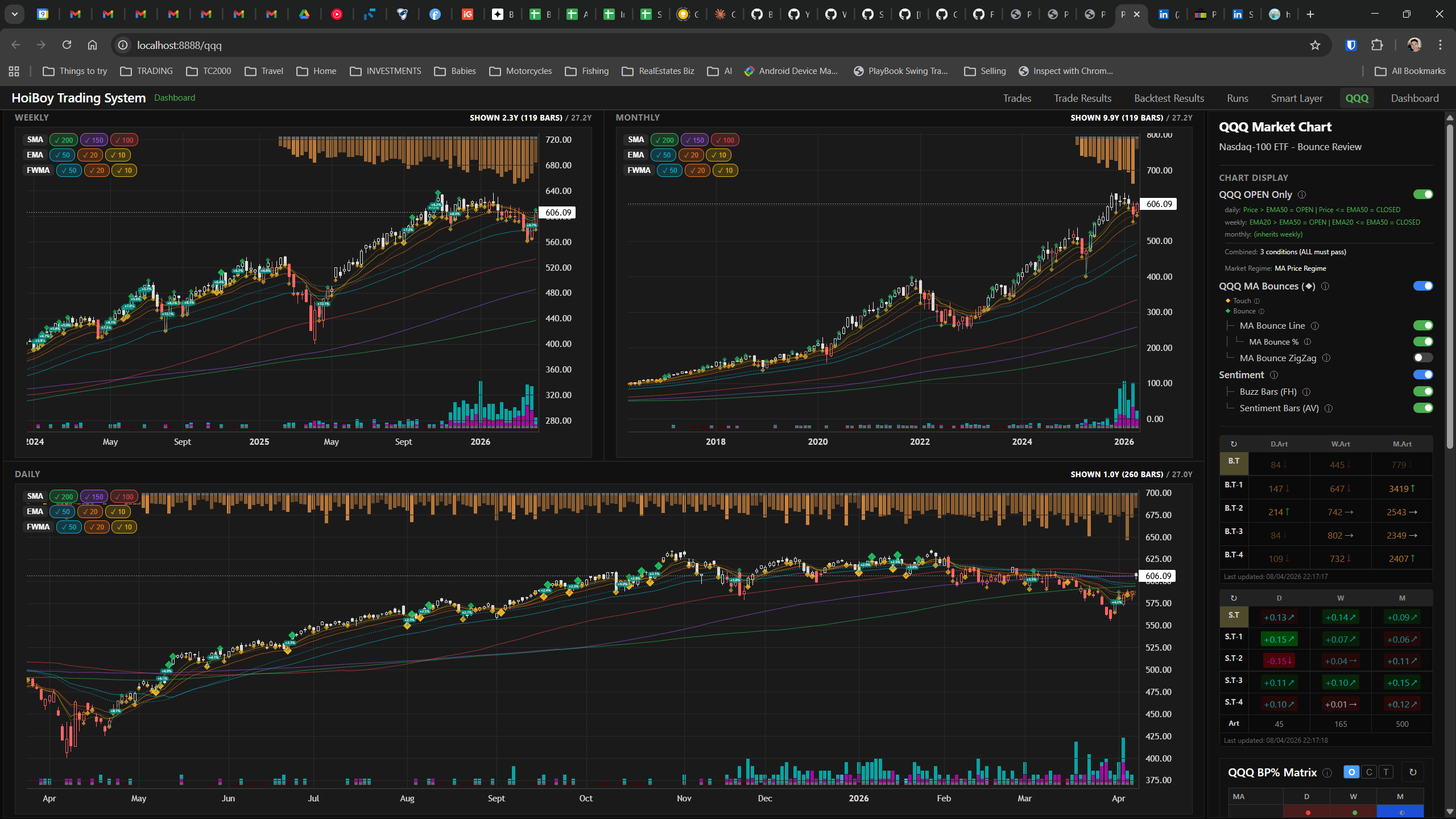
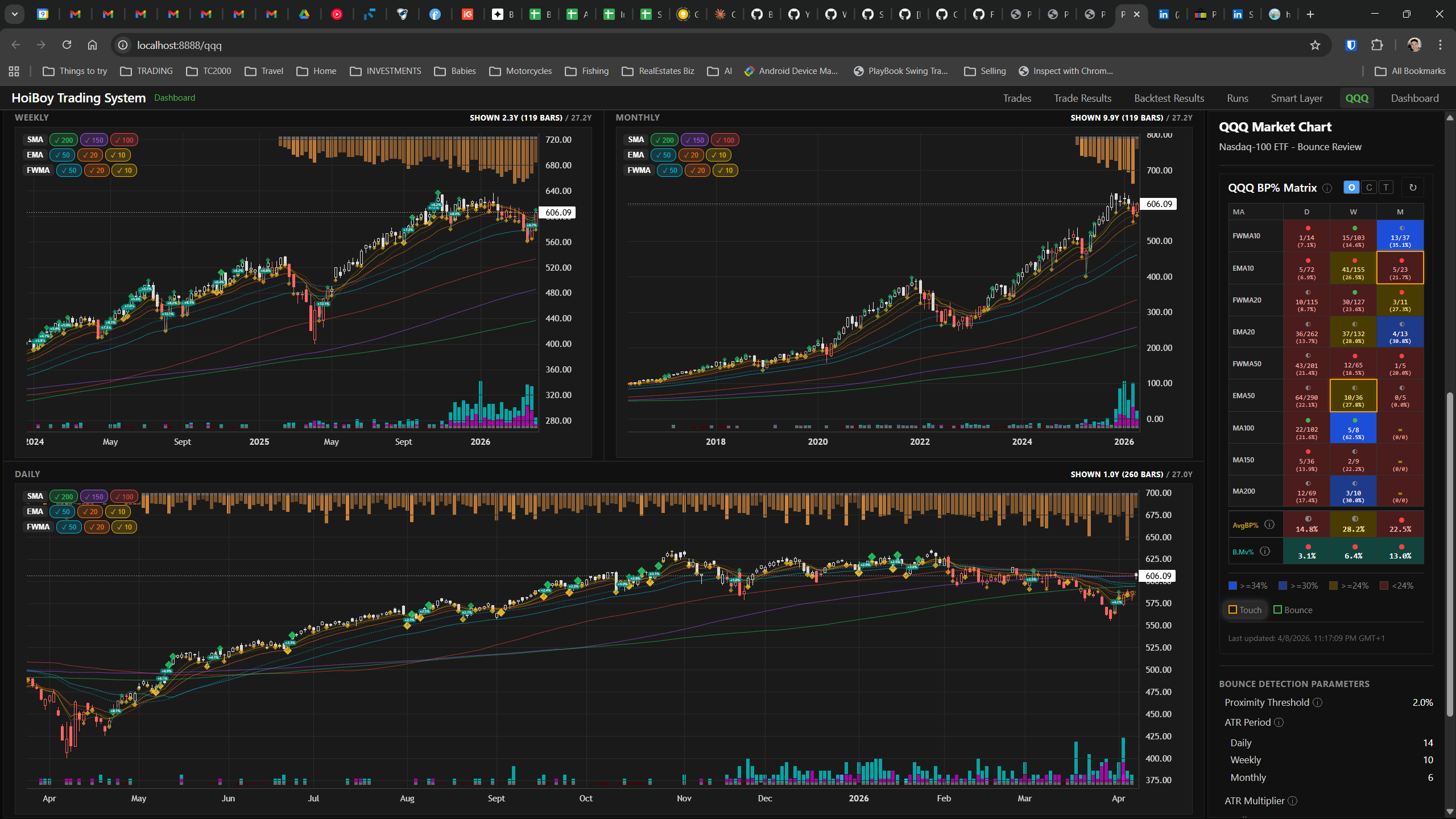
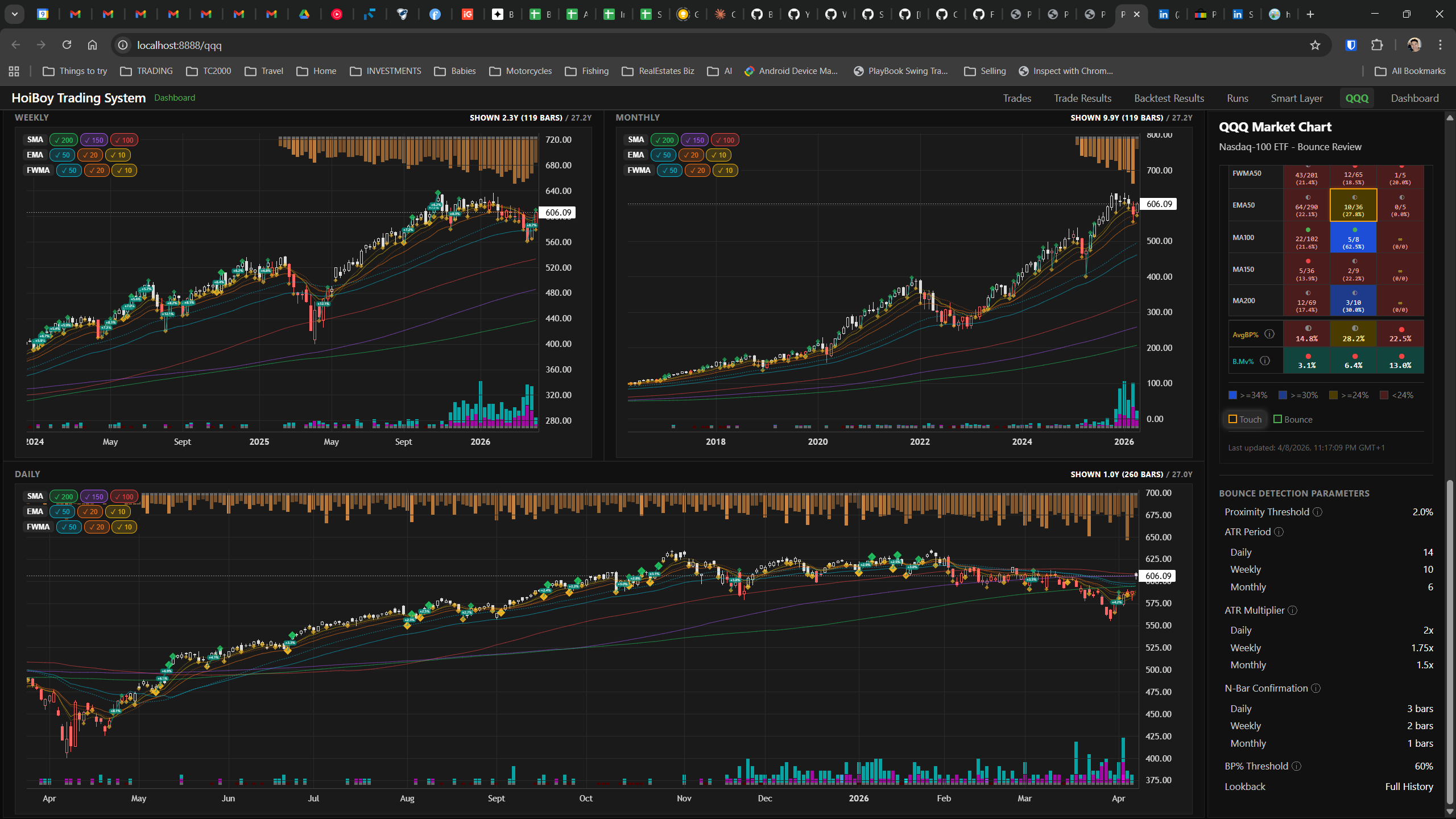
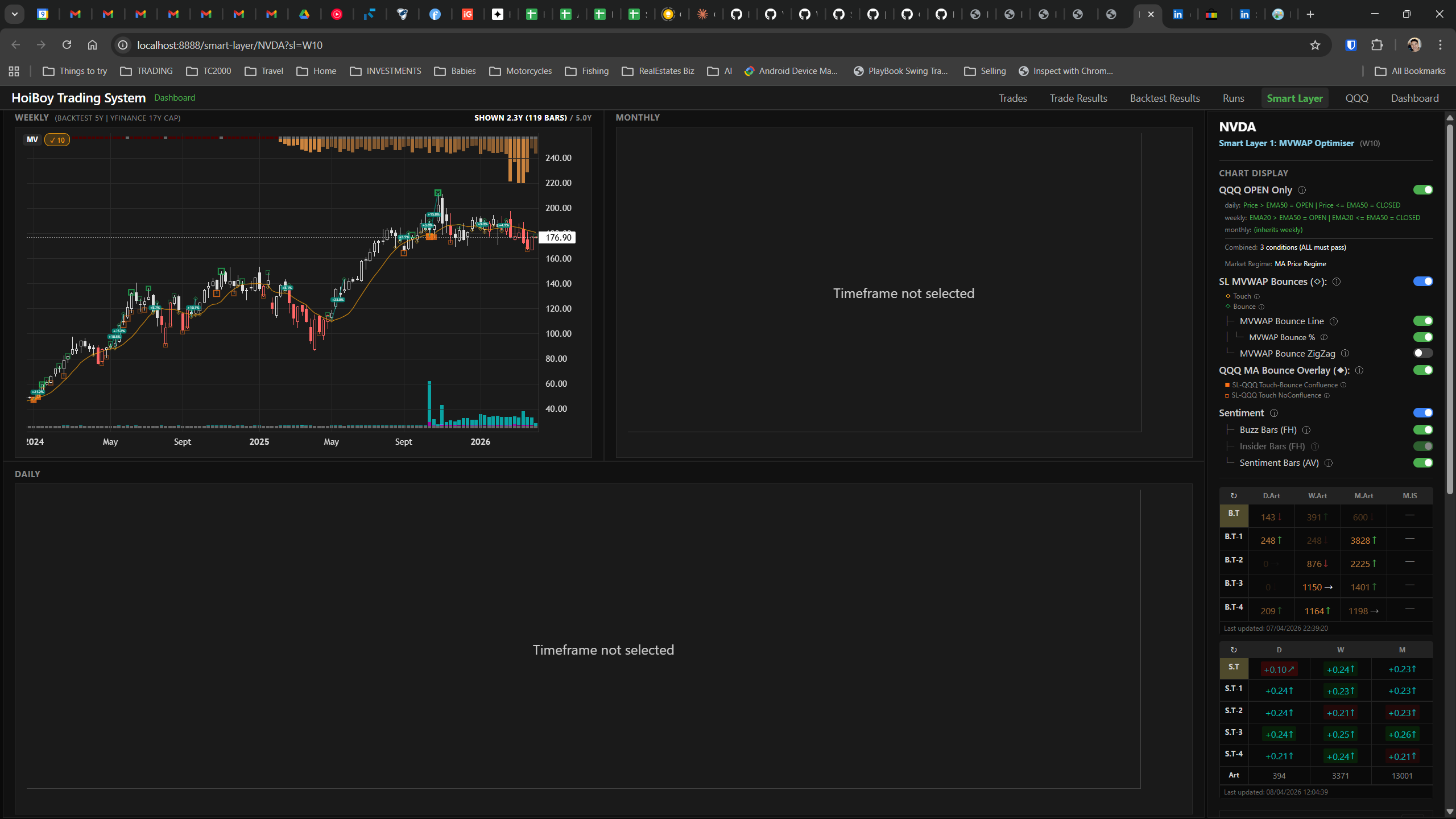
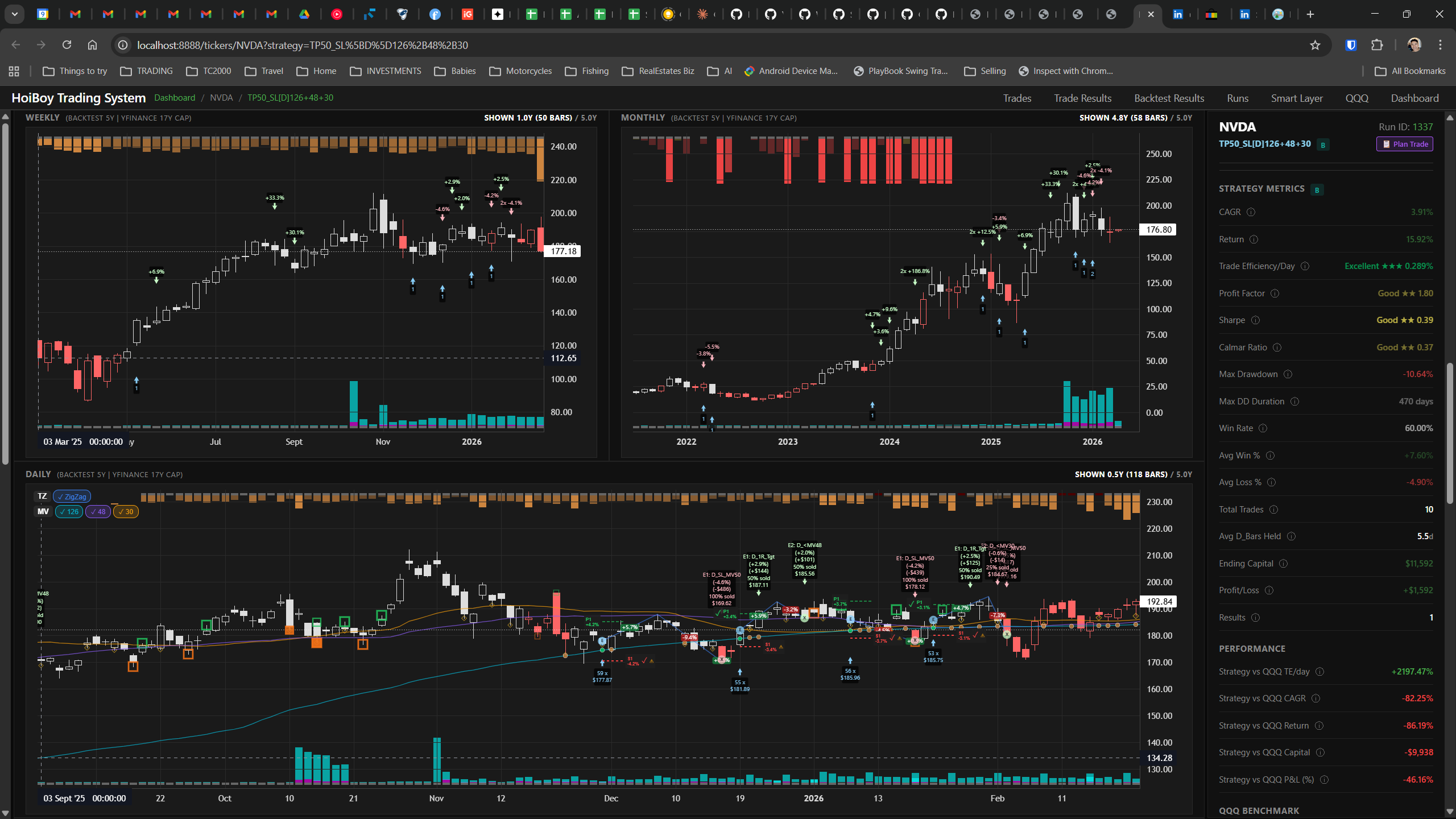
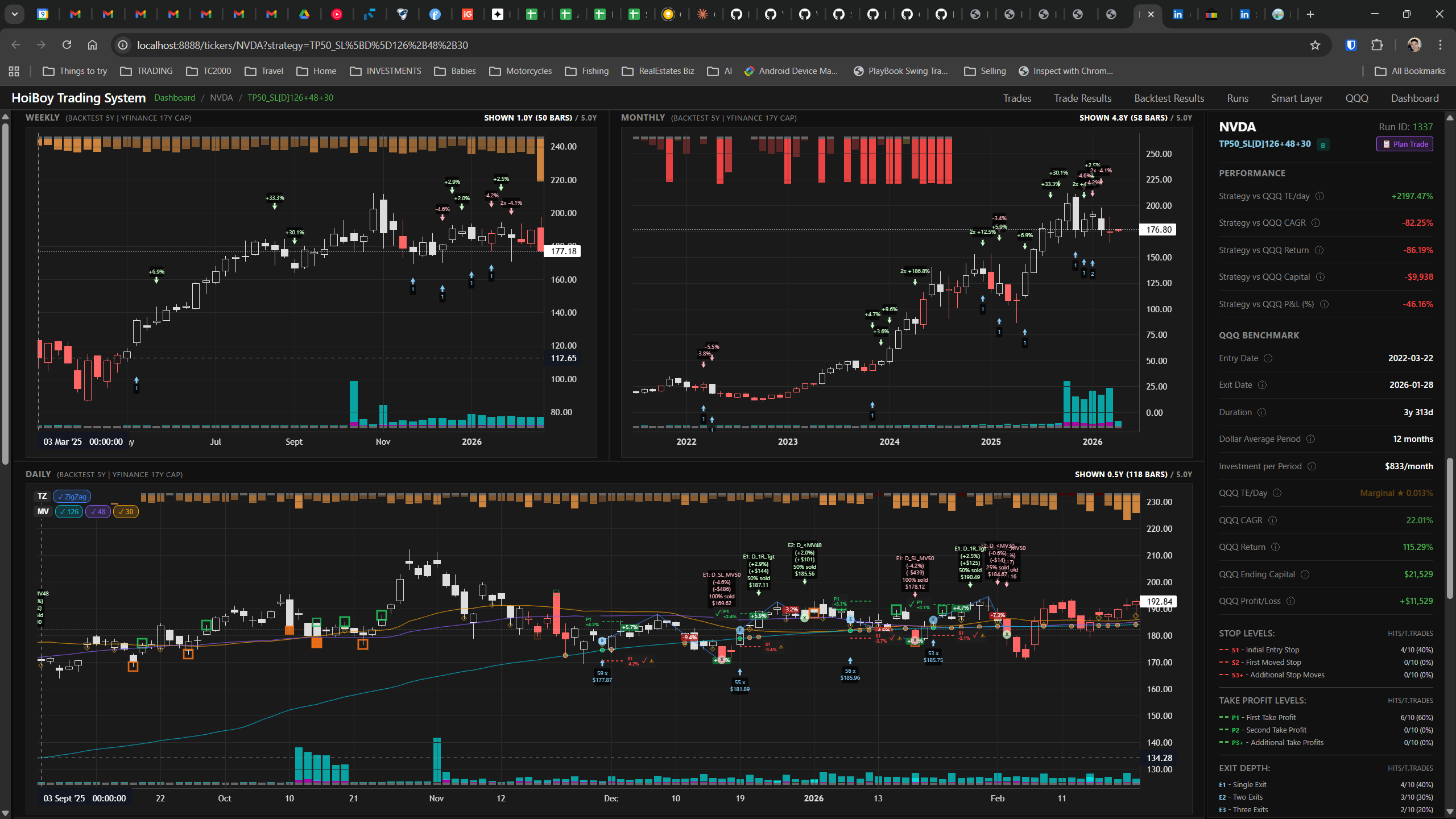
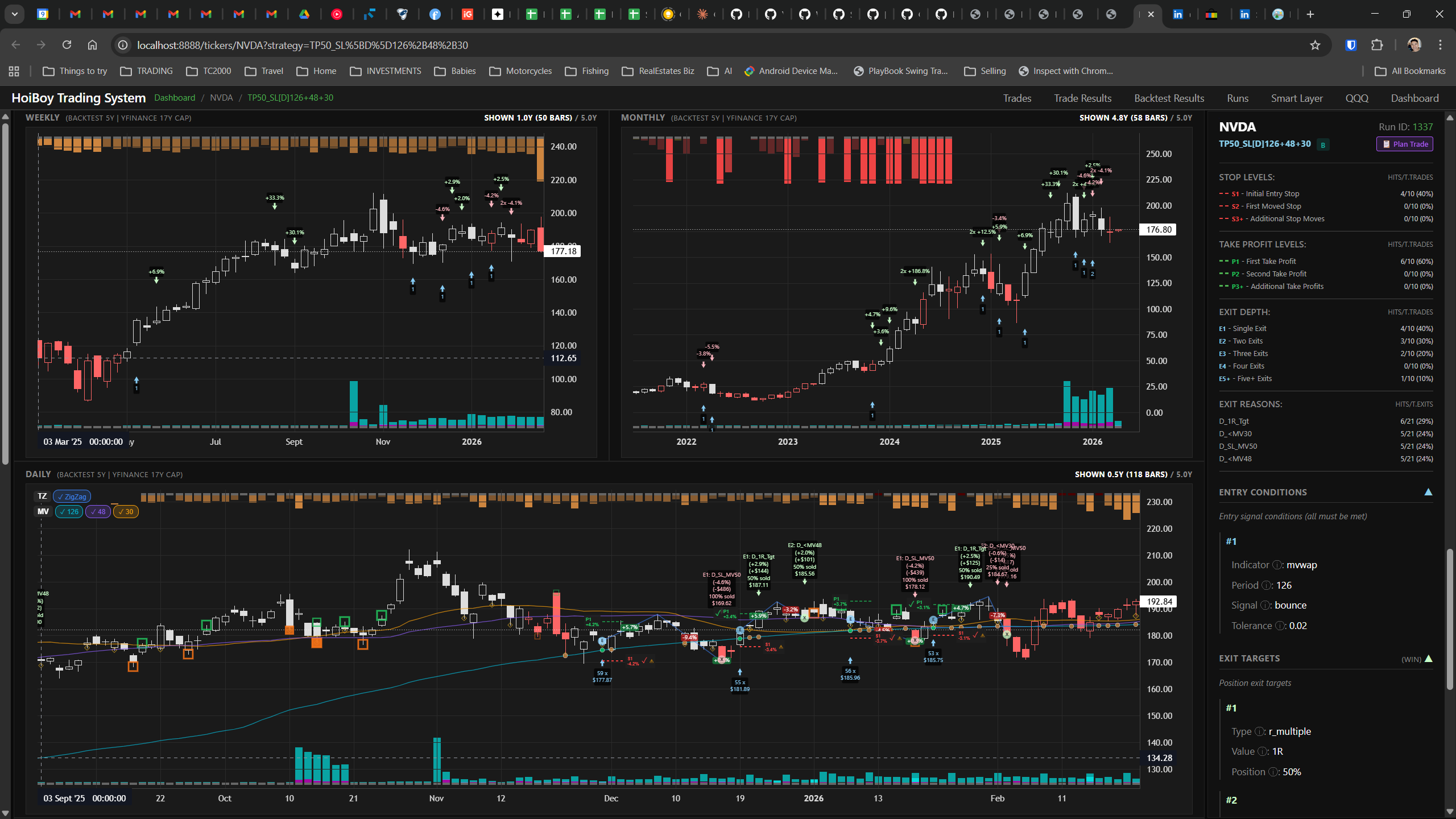
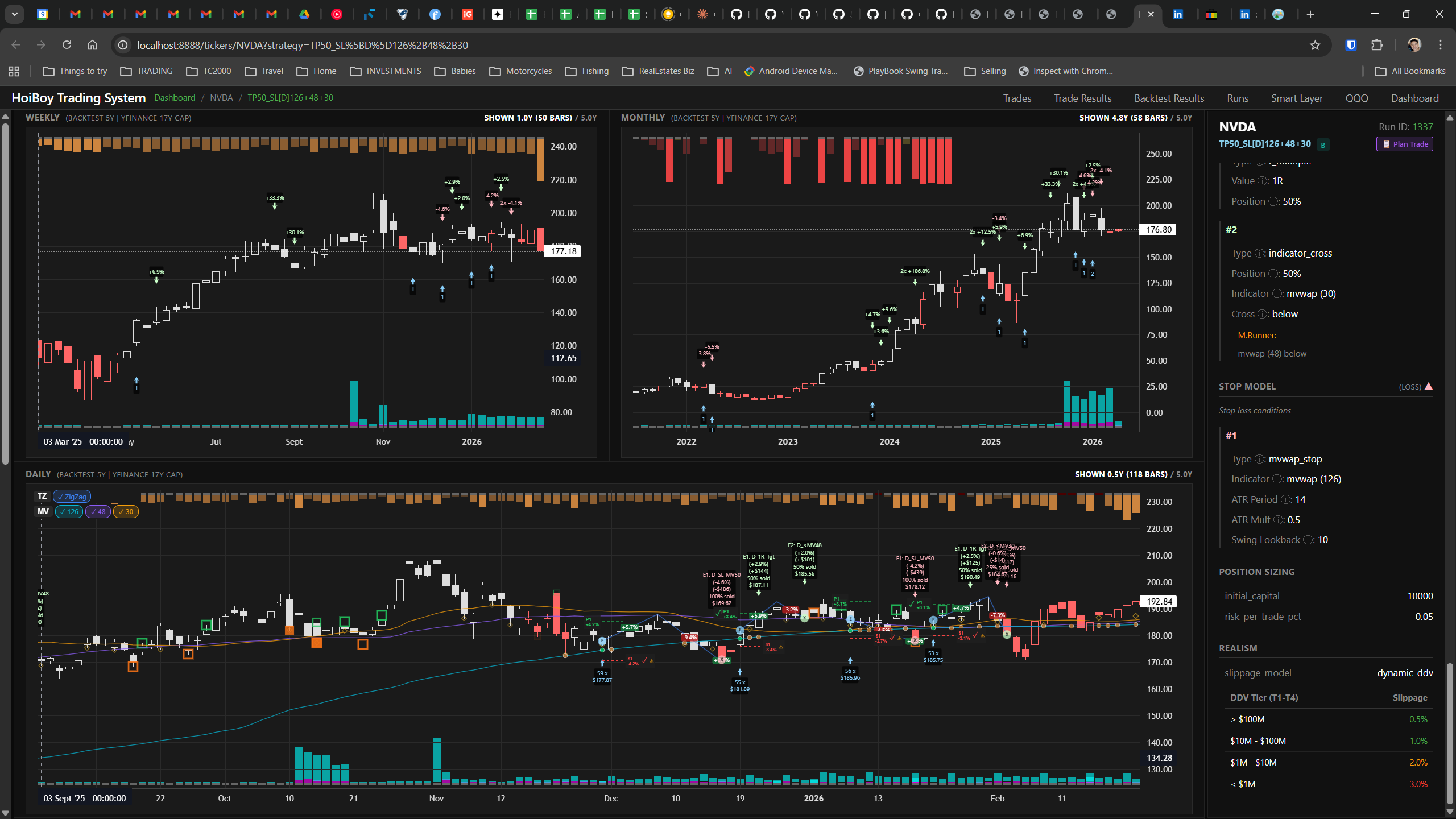
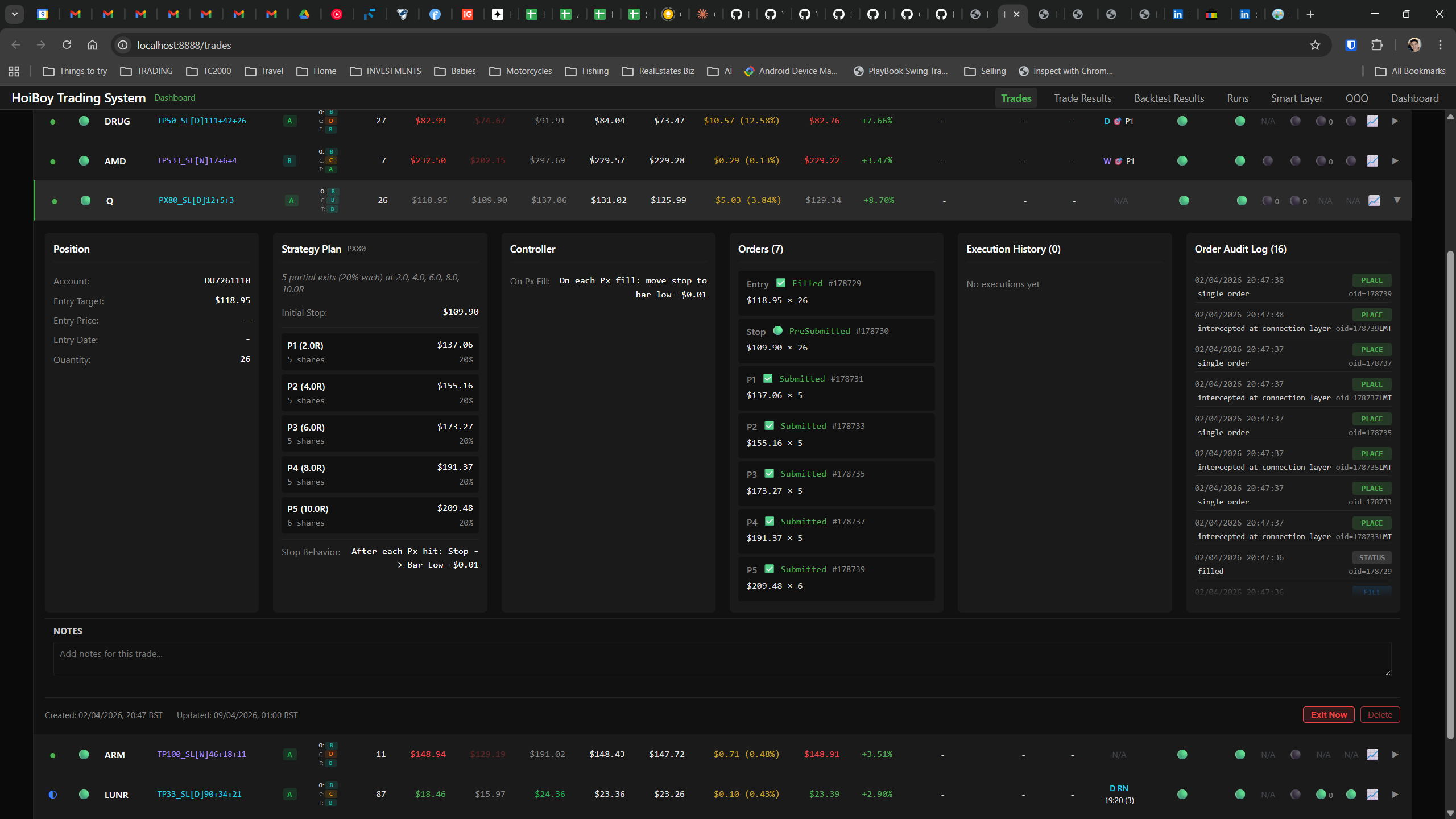
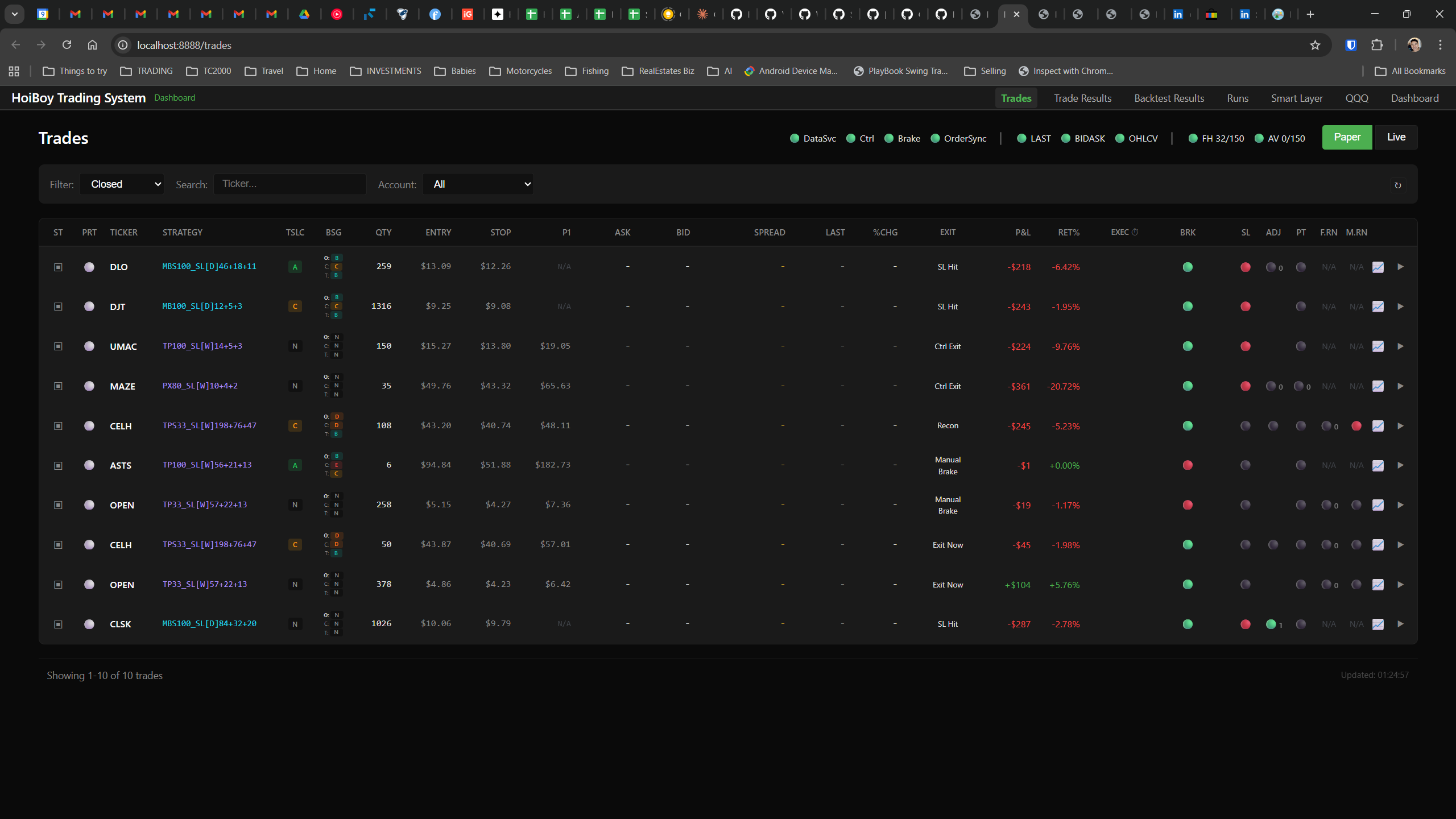
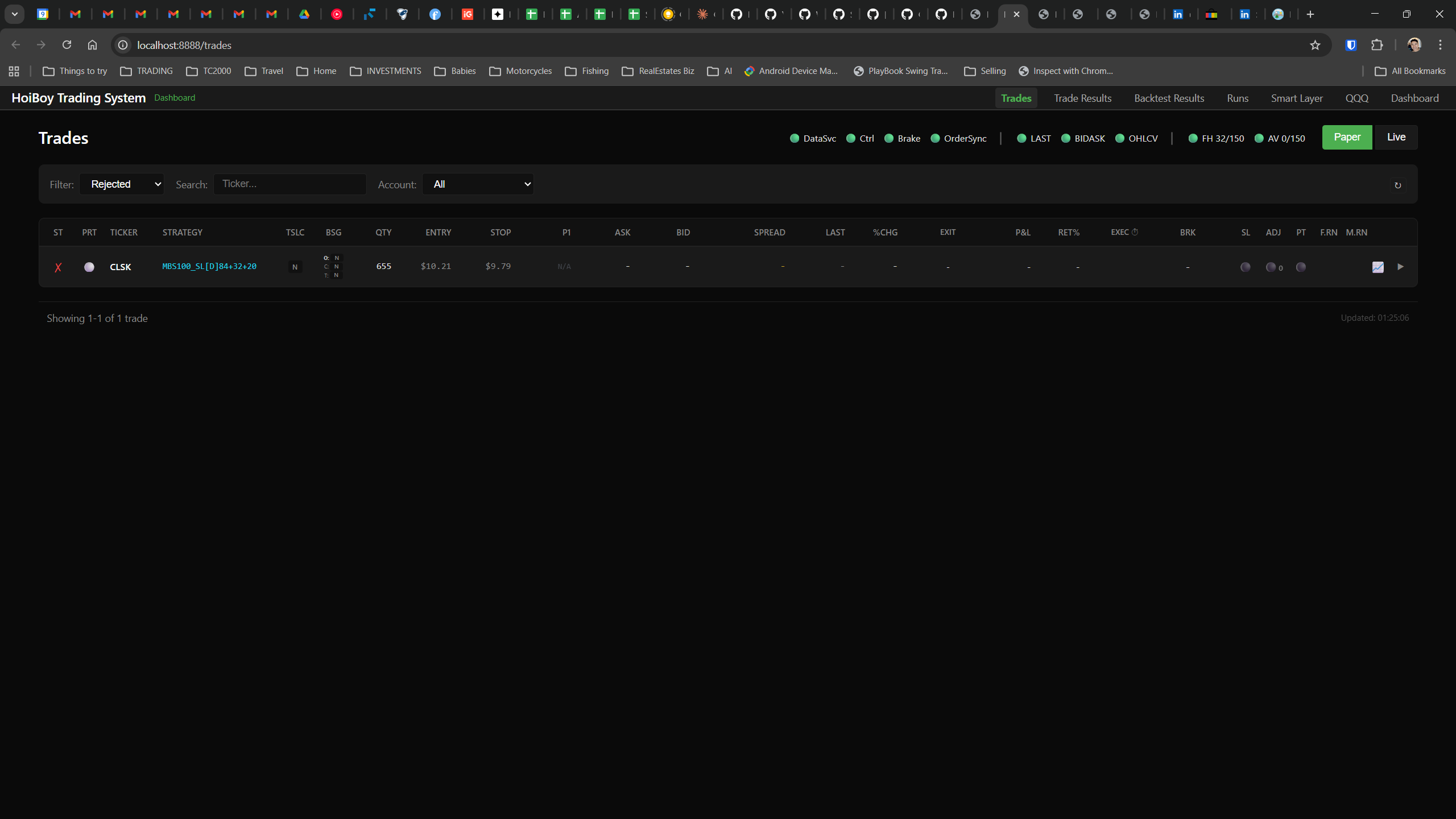
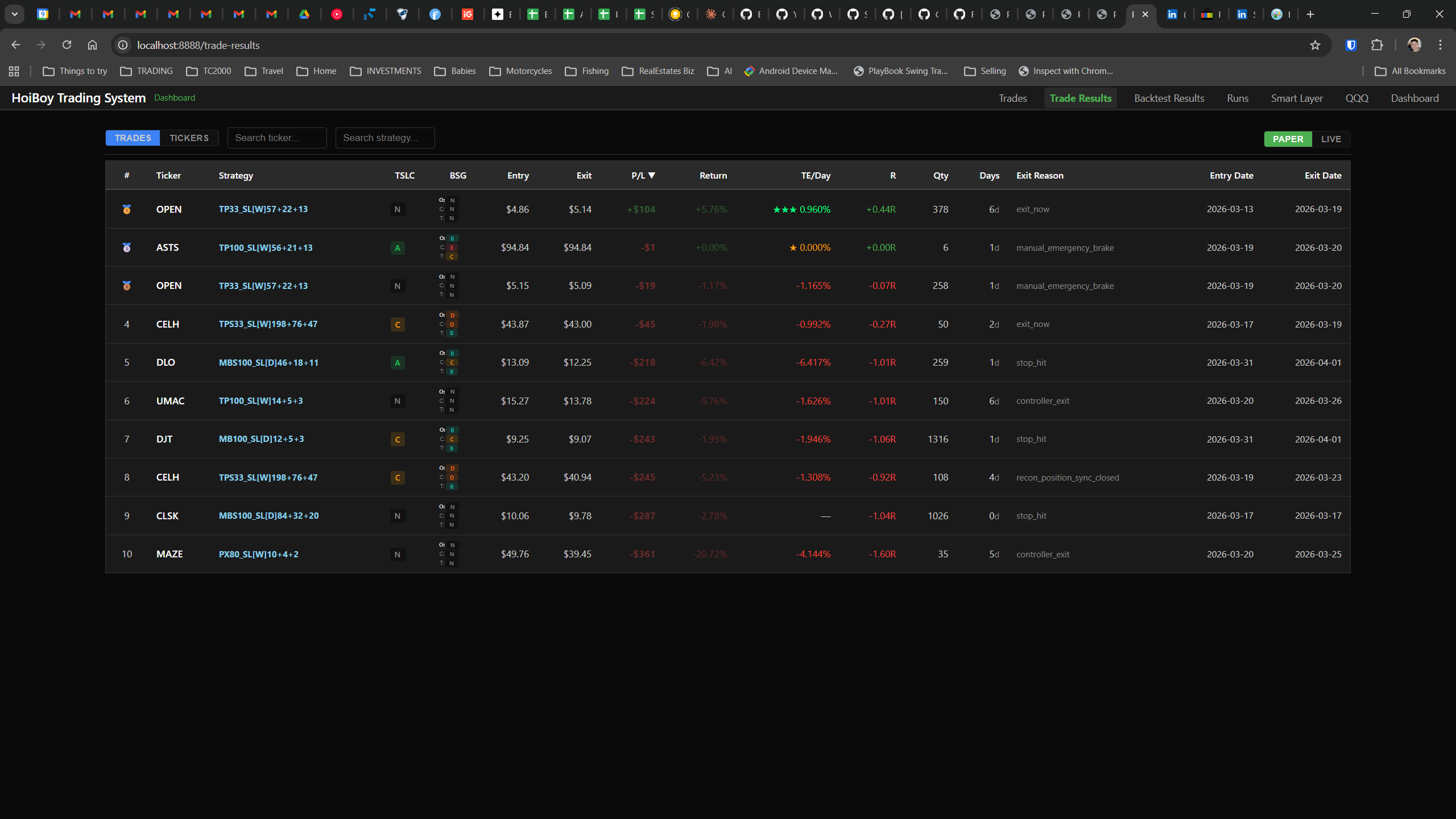
This is what production looks like. Not the code. Not the architecture diagrams. The actual running system.
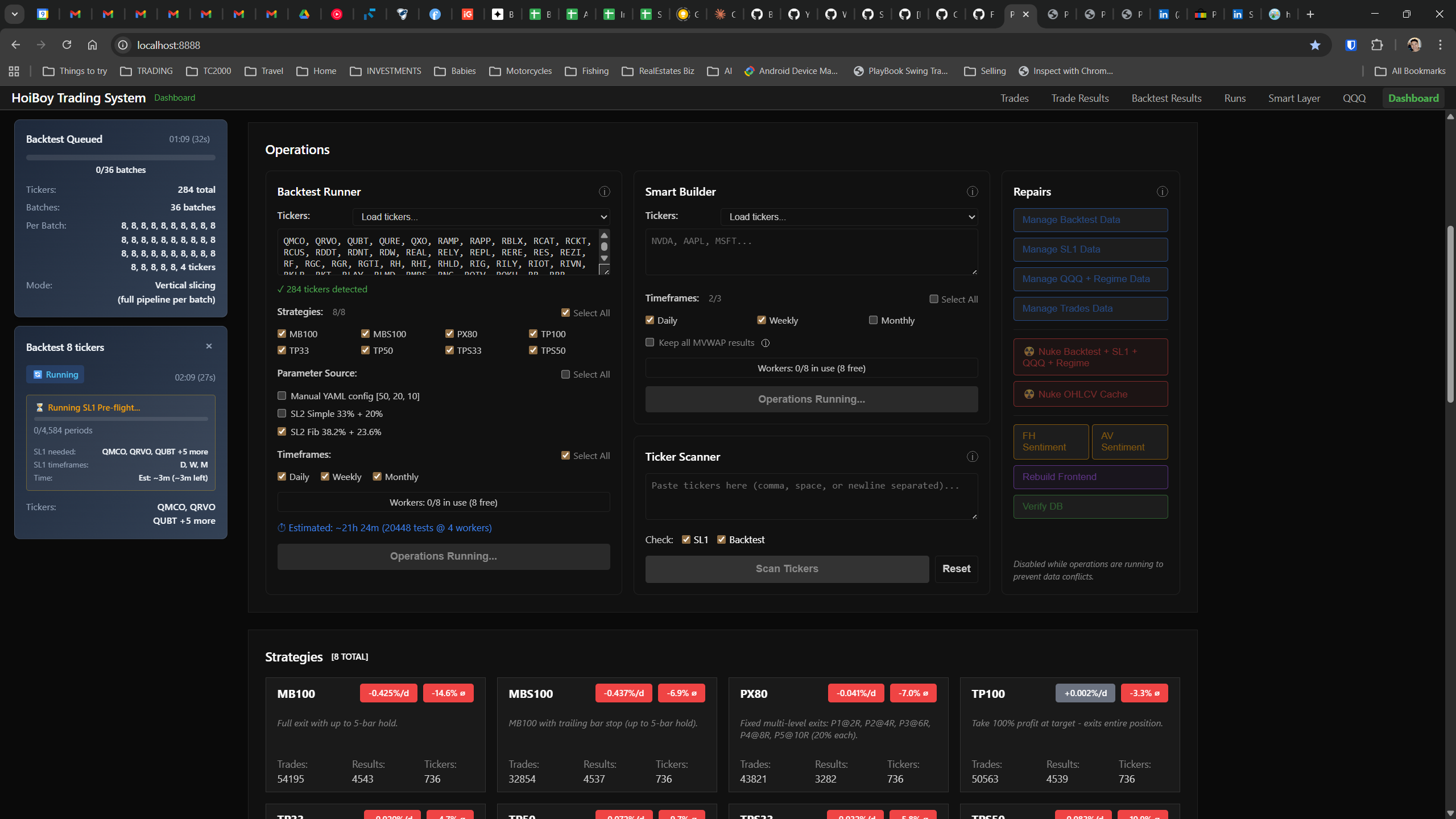
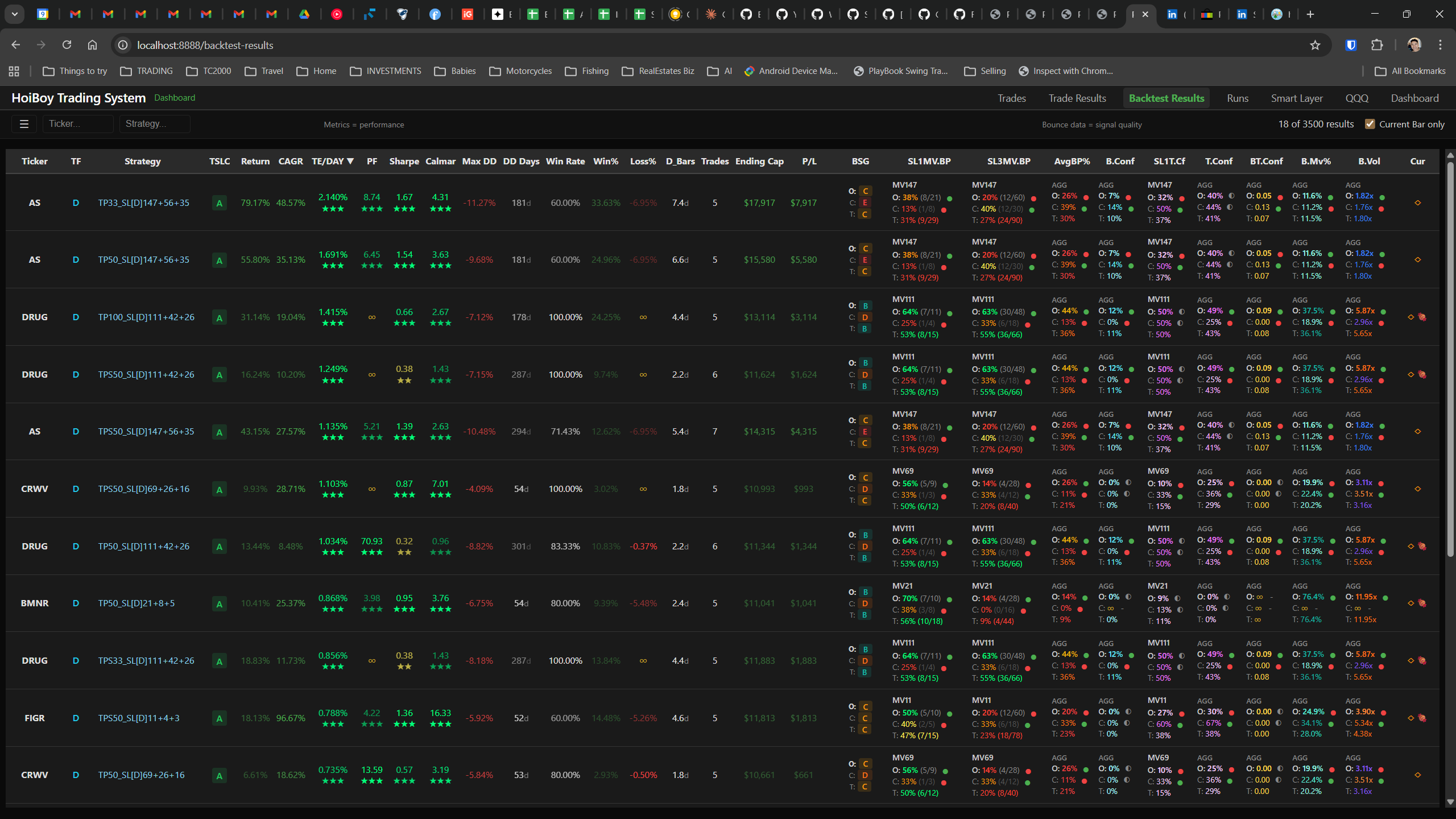
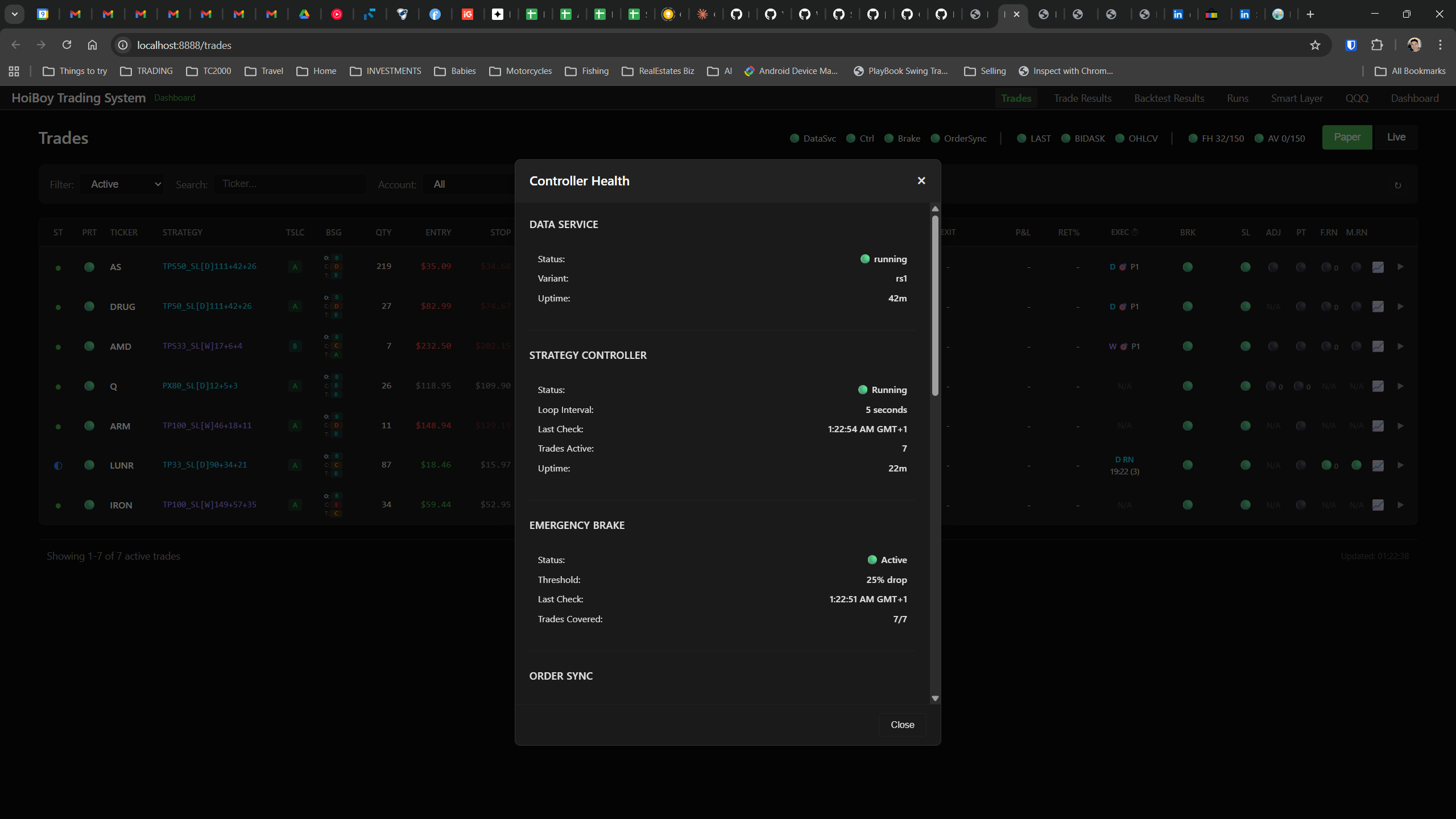
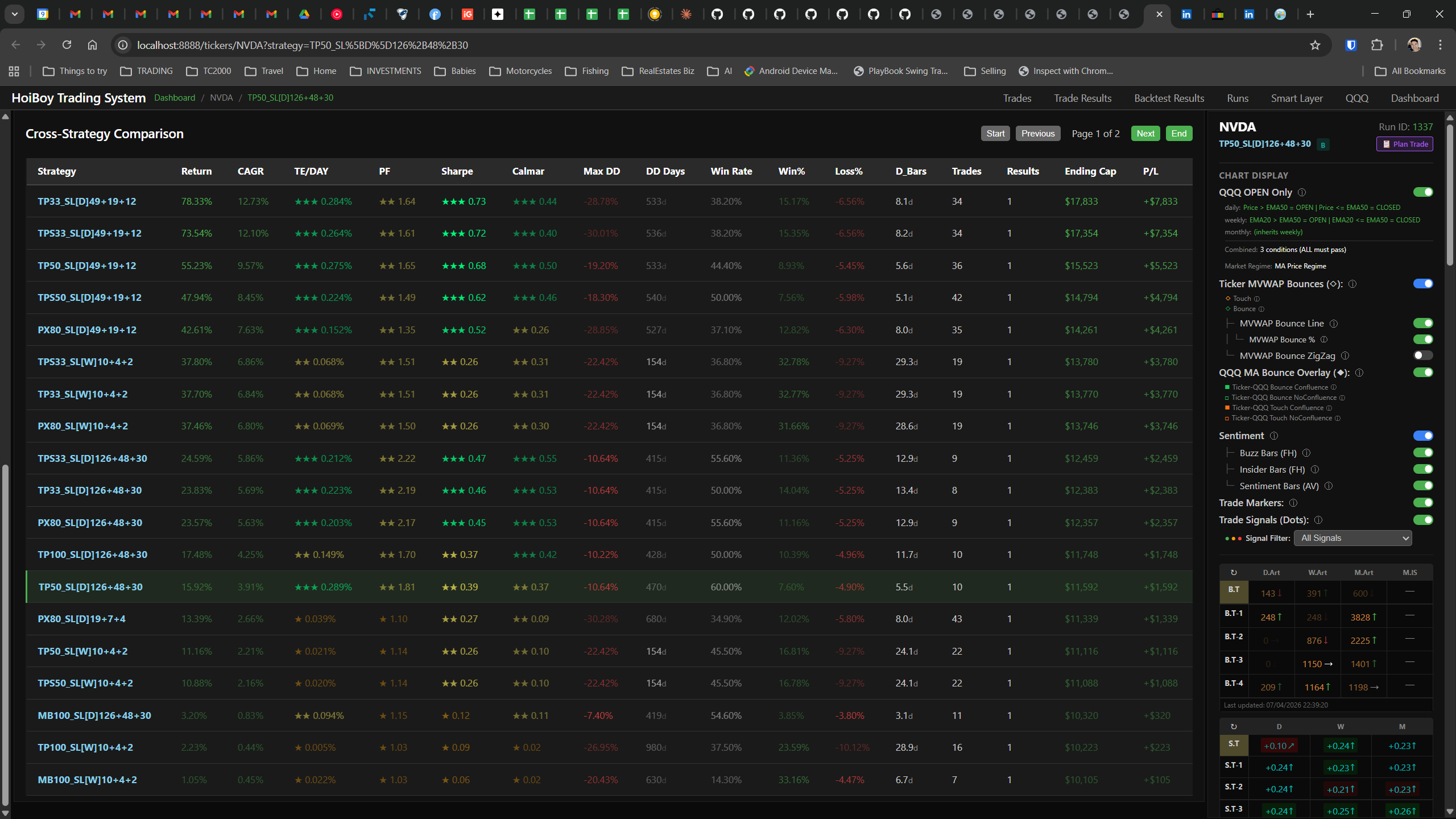
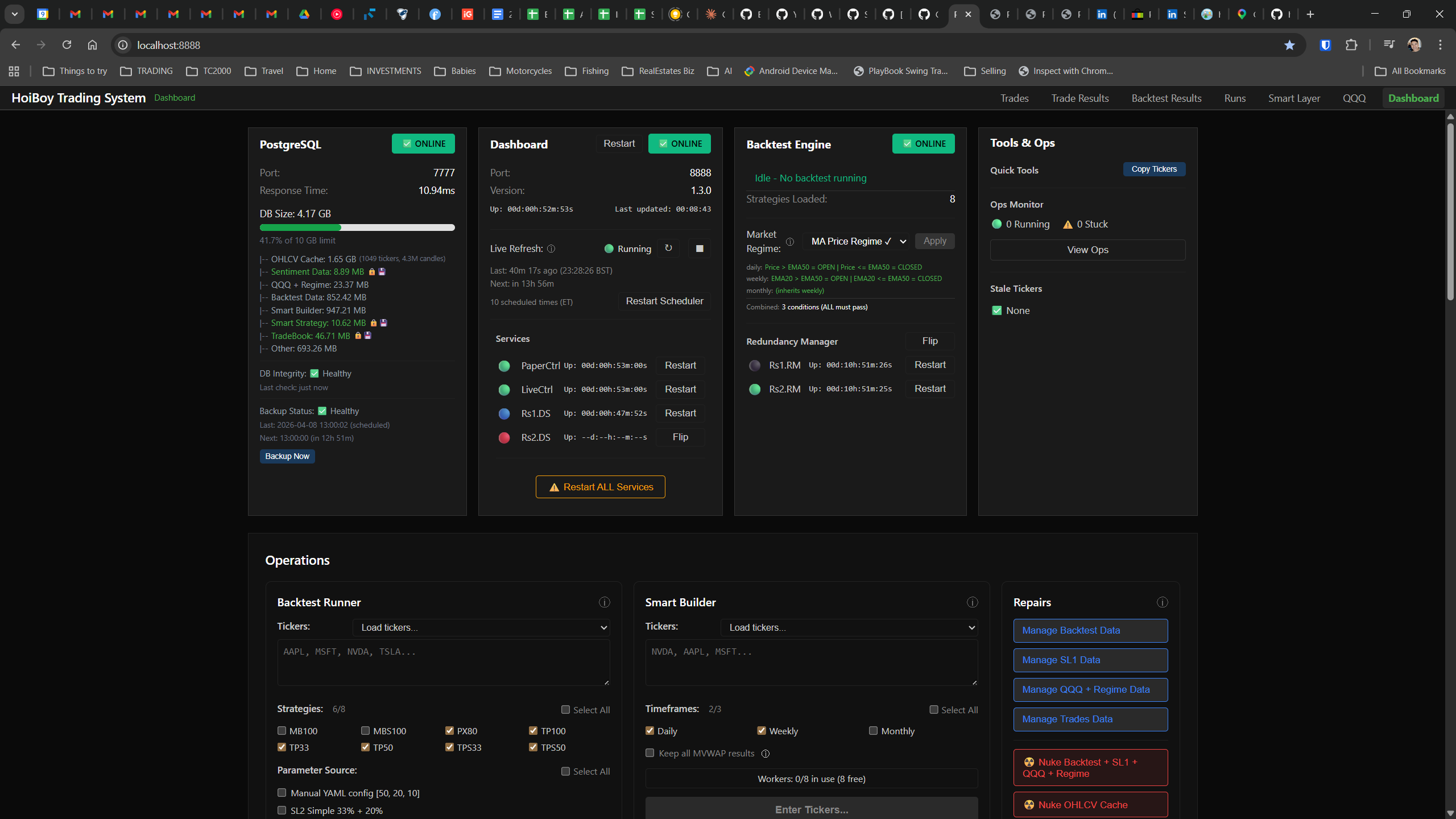
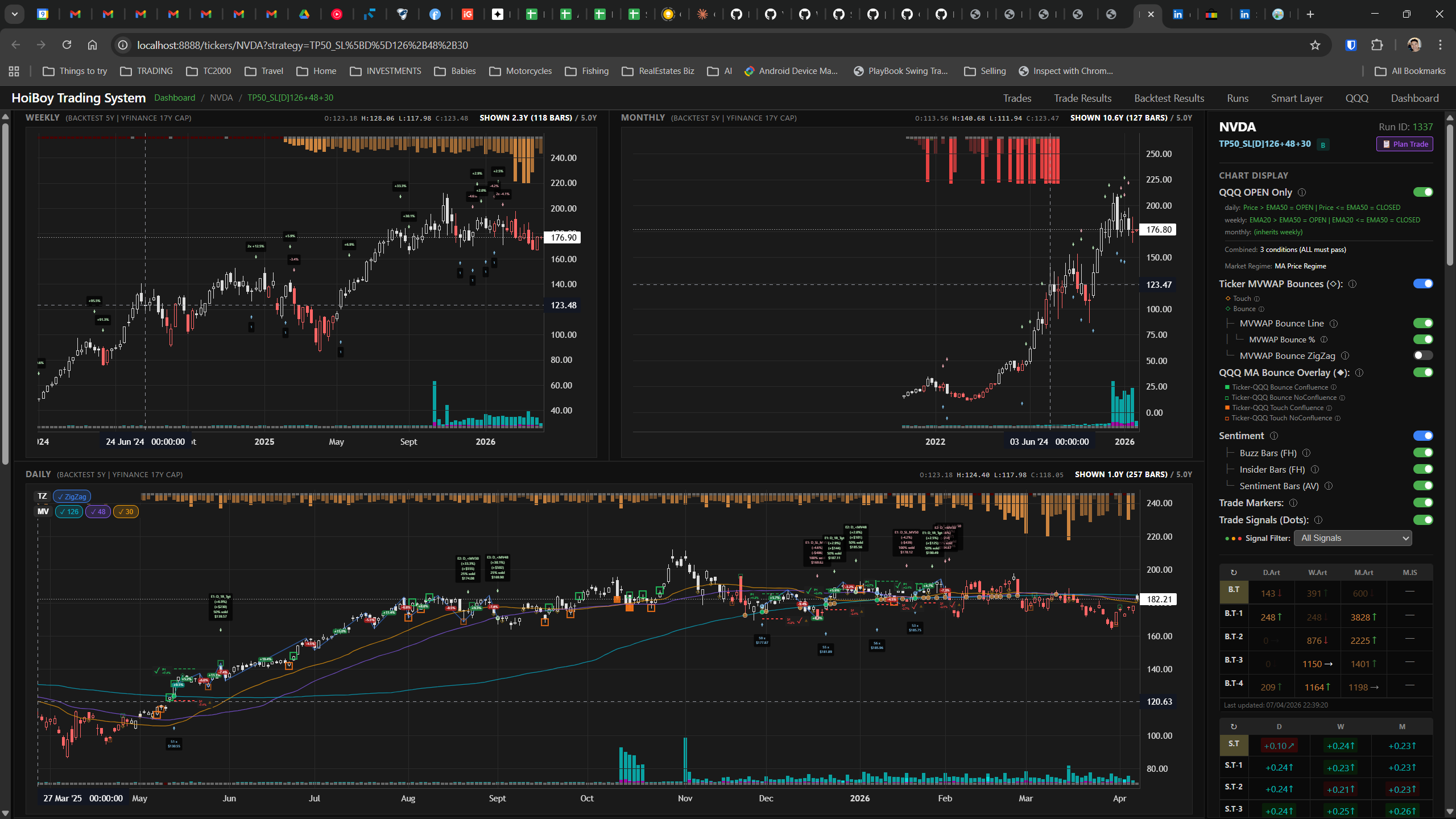
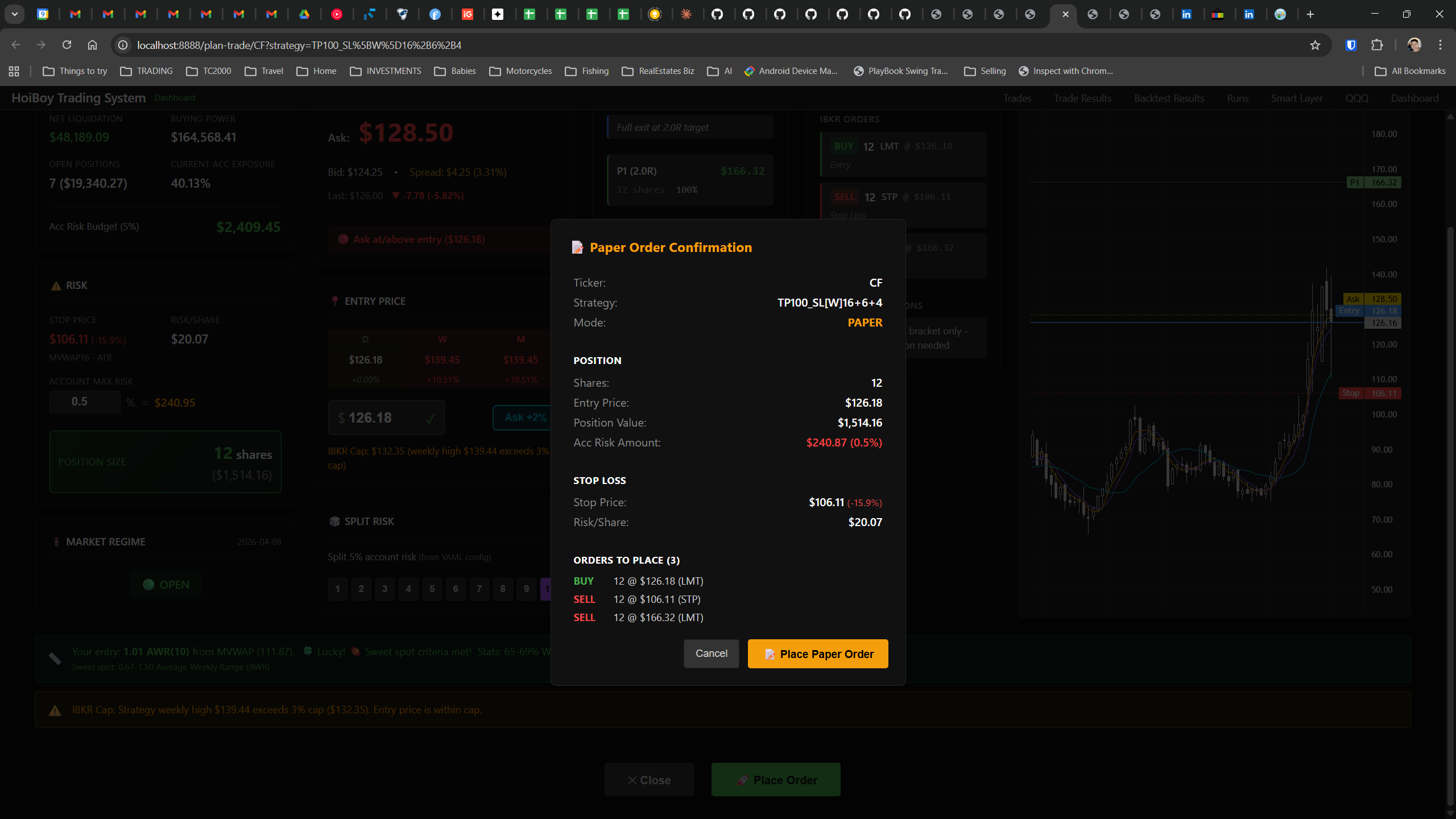
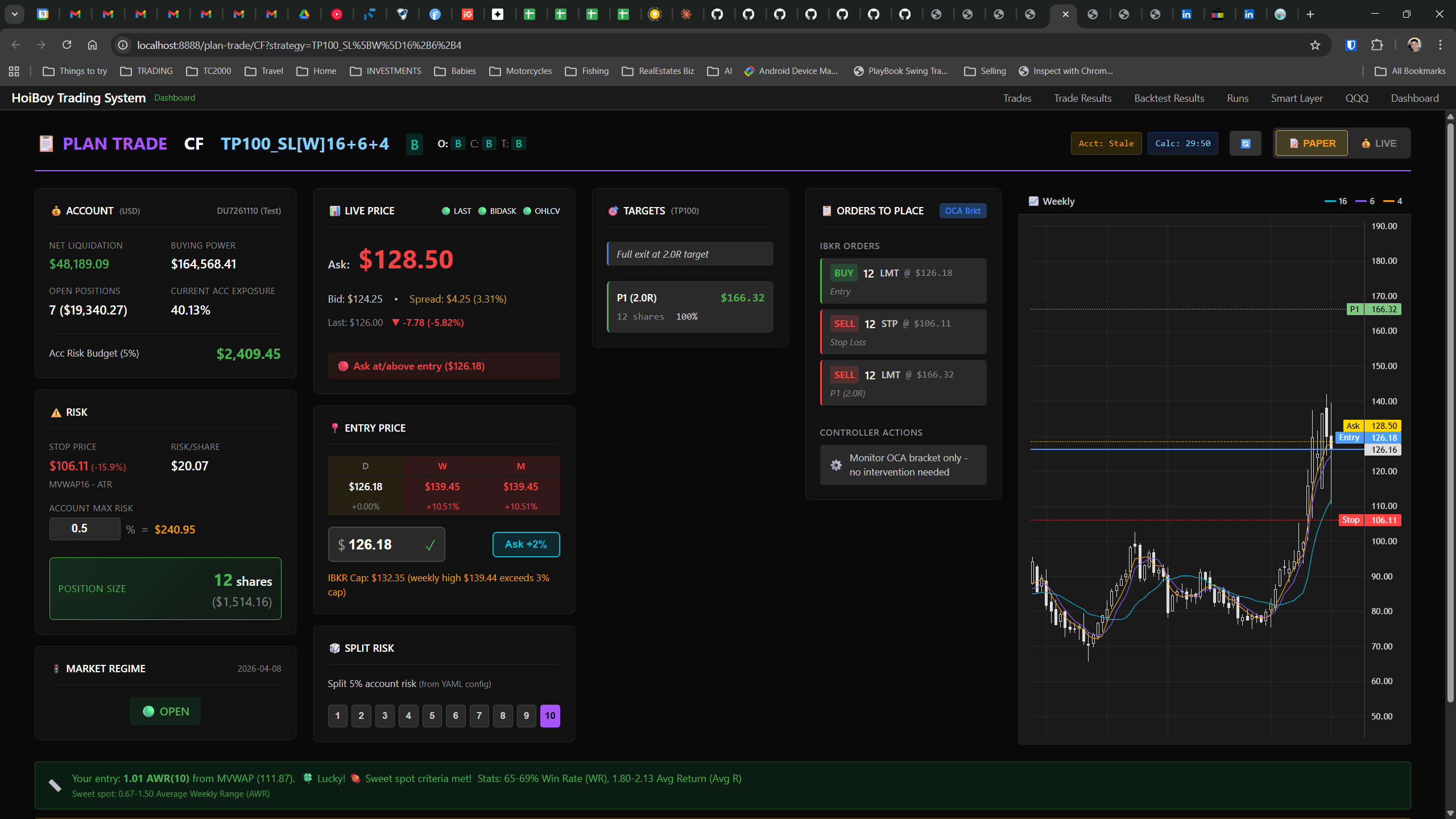
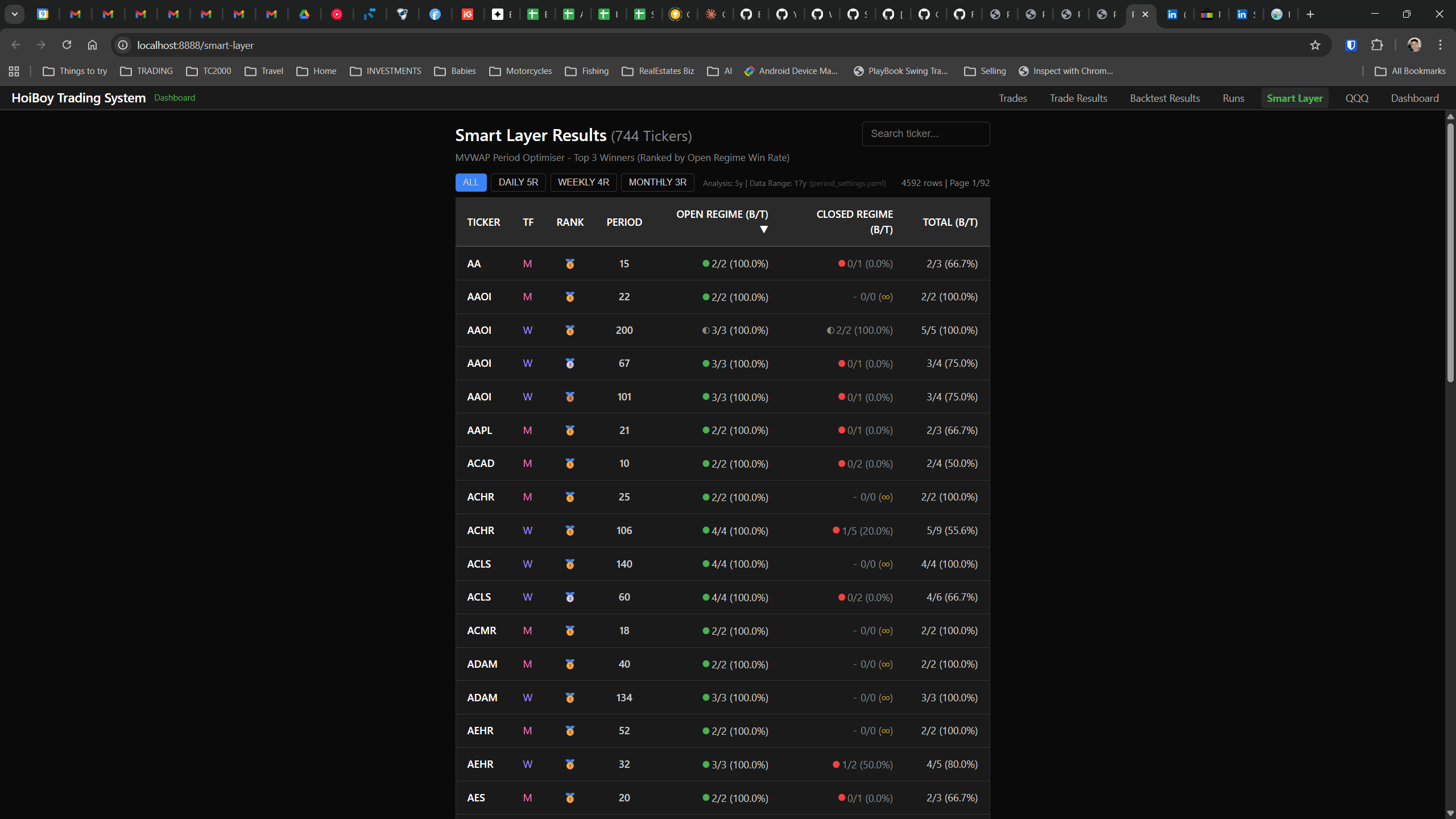
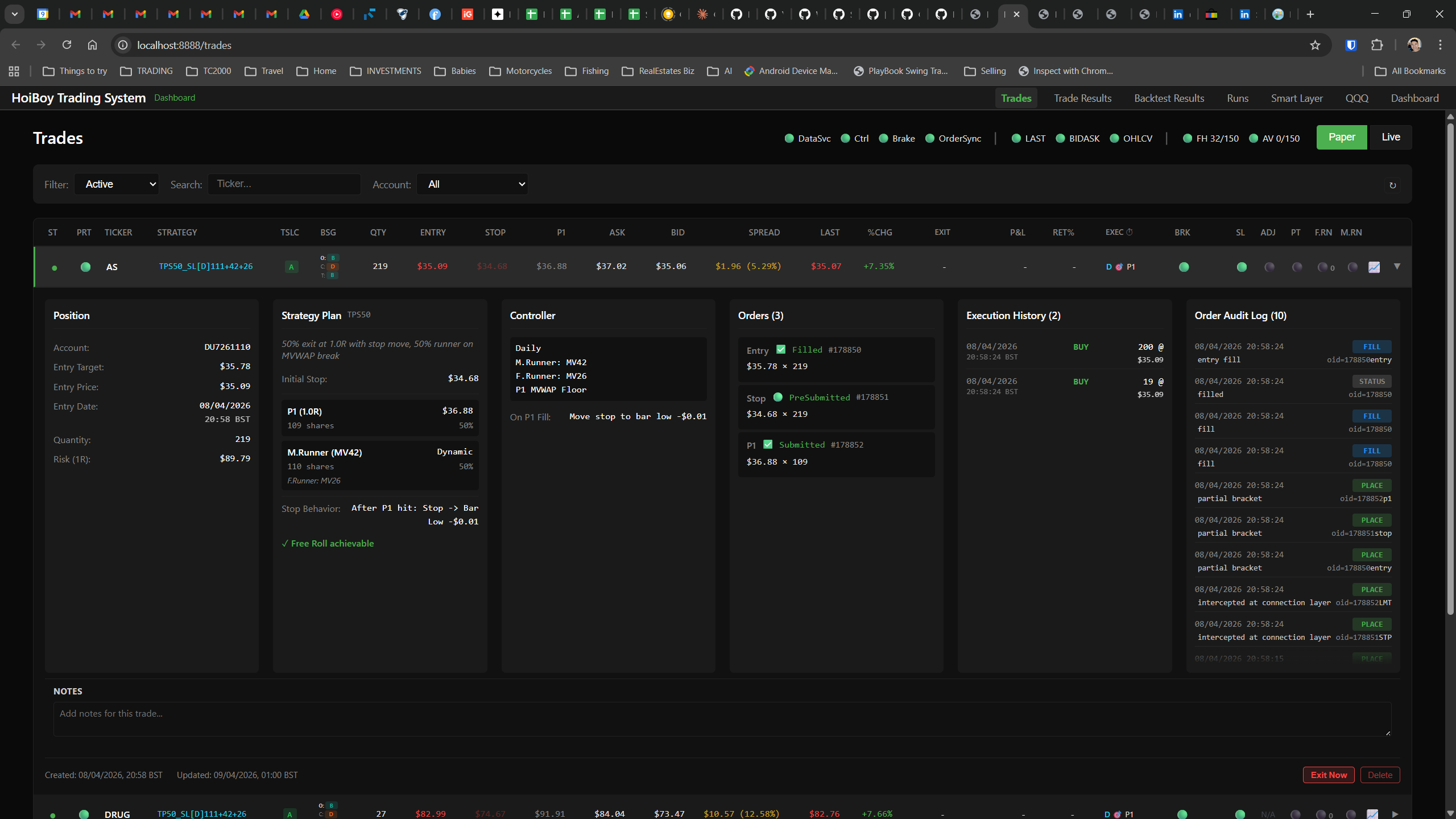
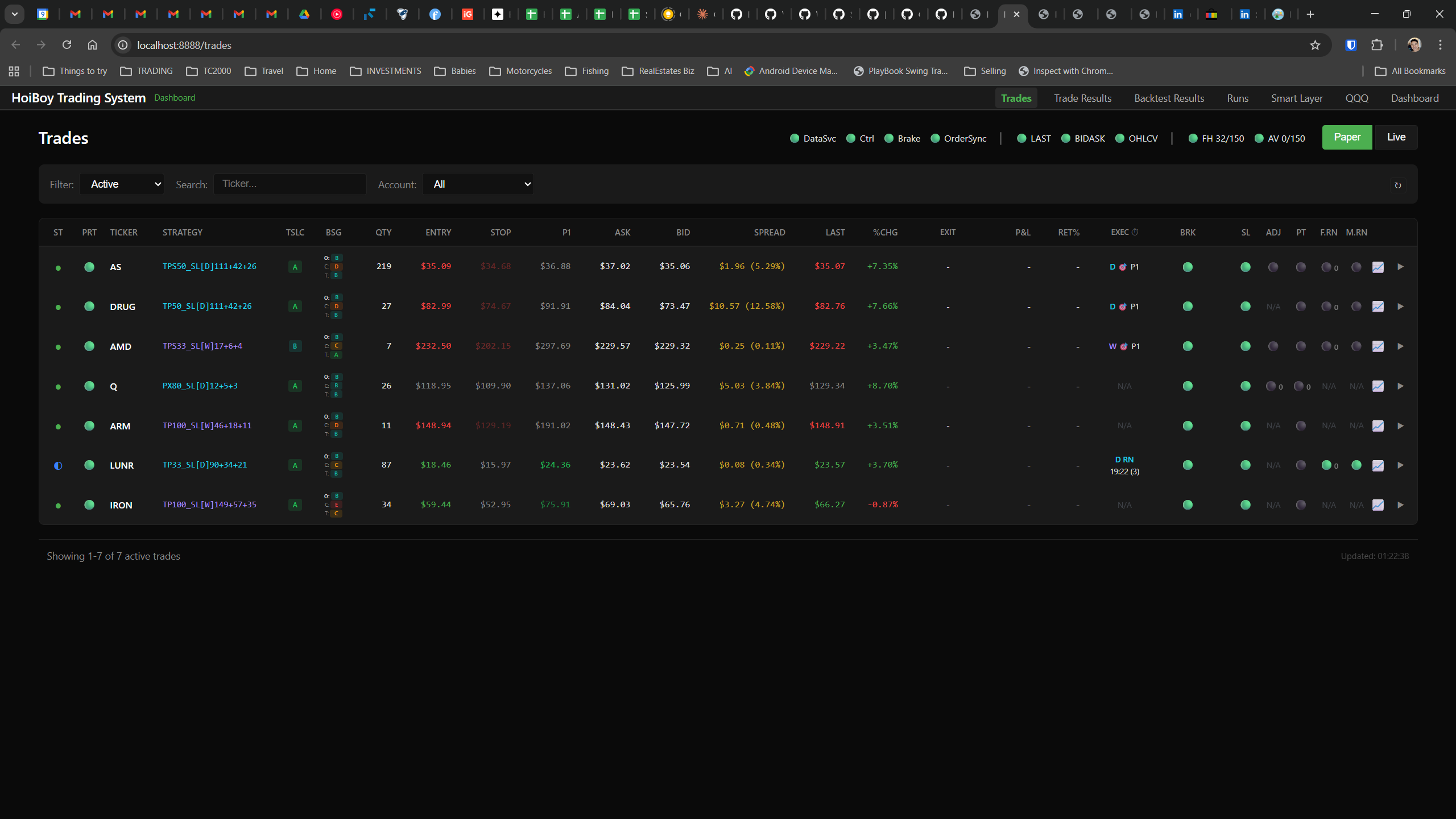
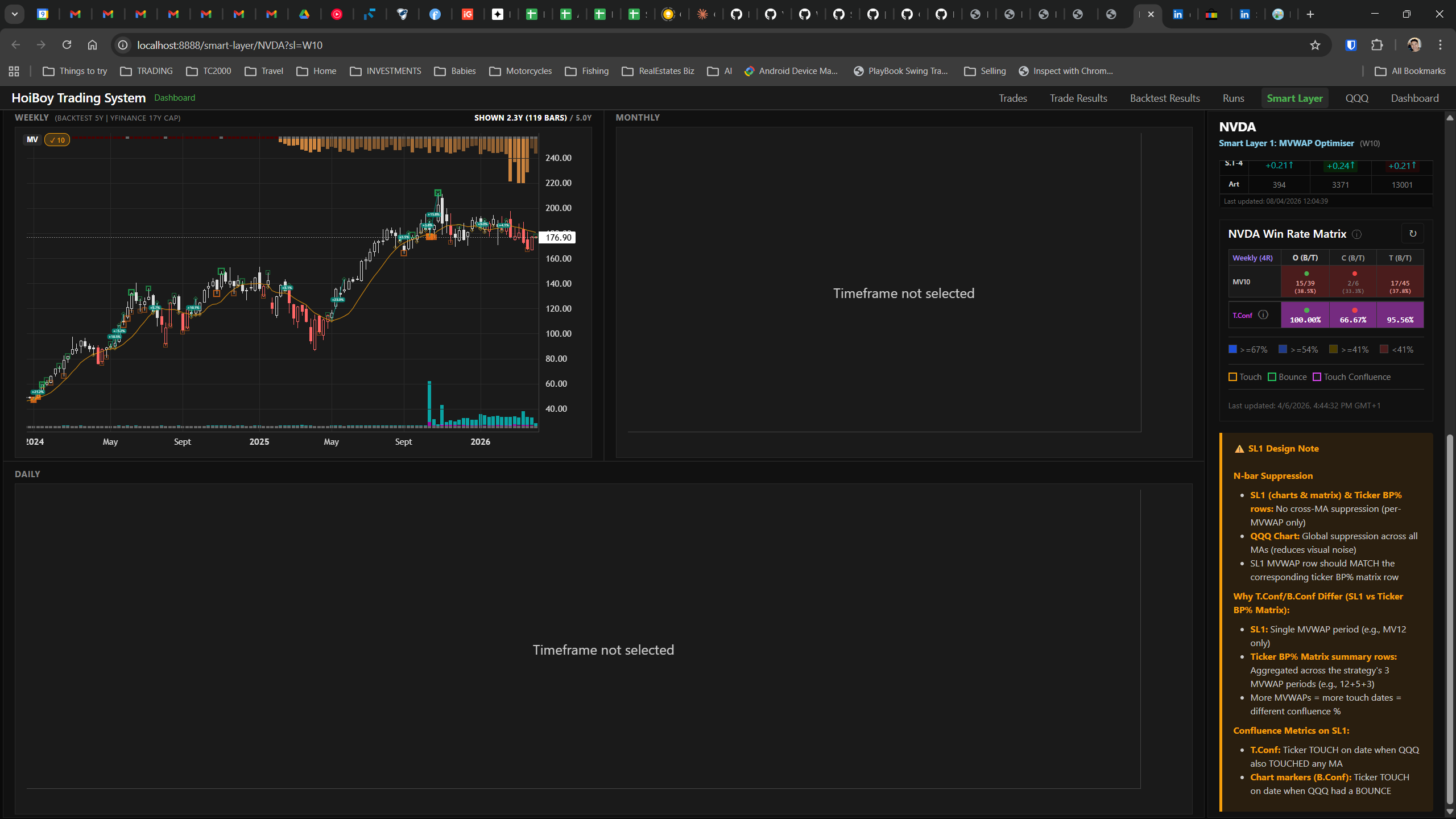
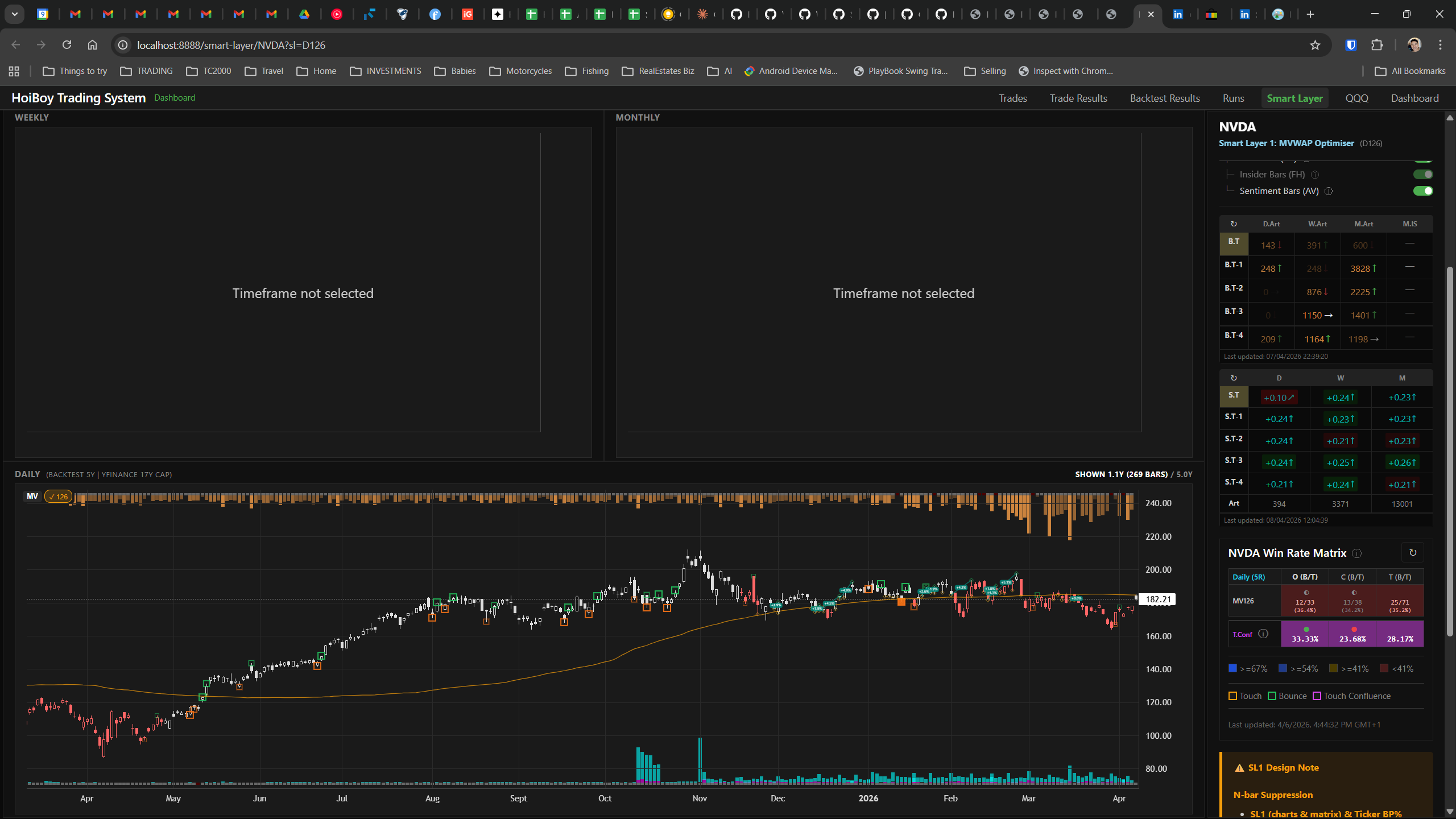
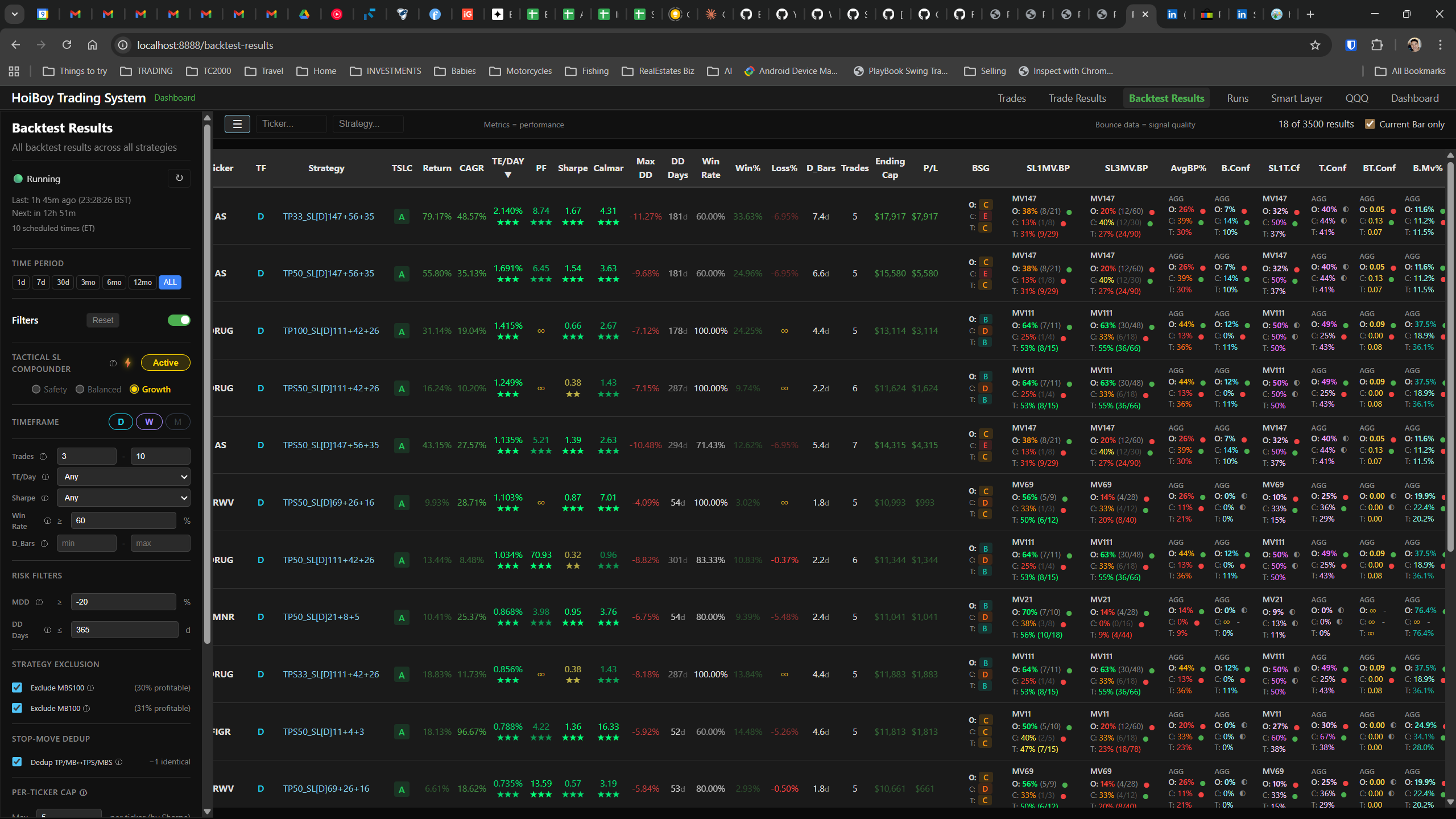
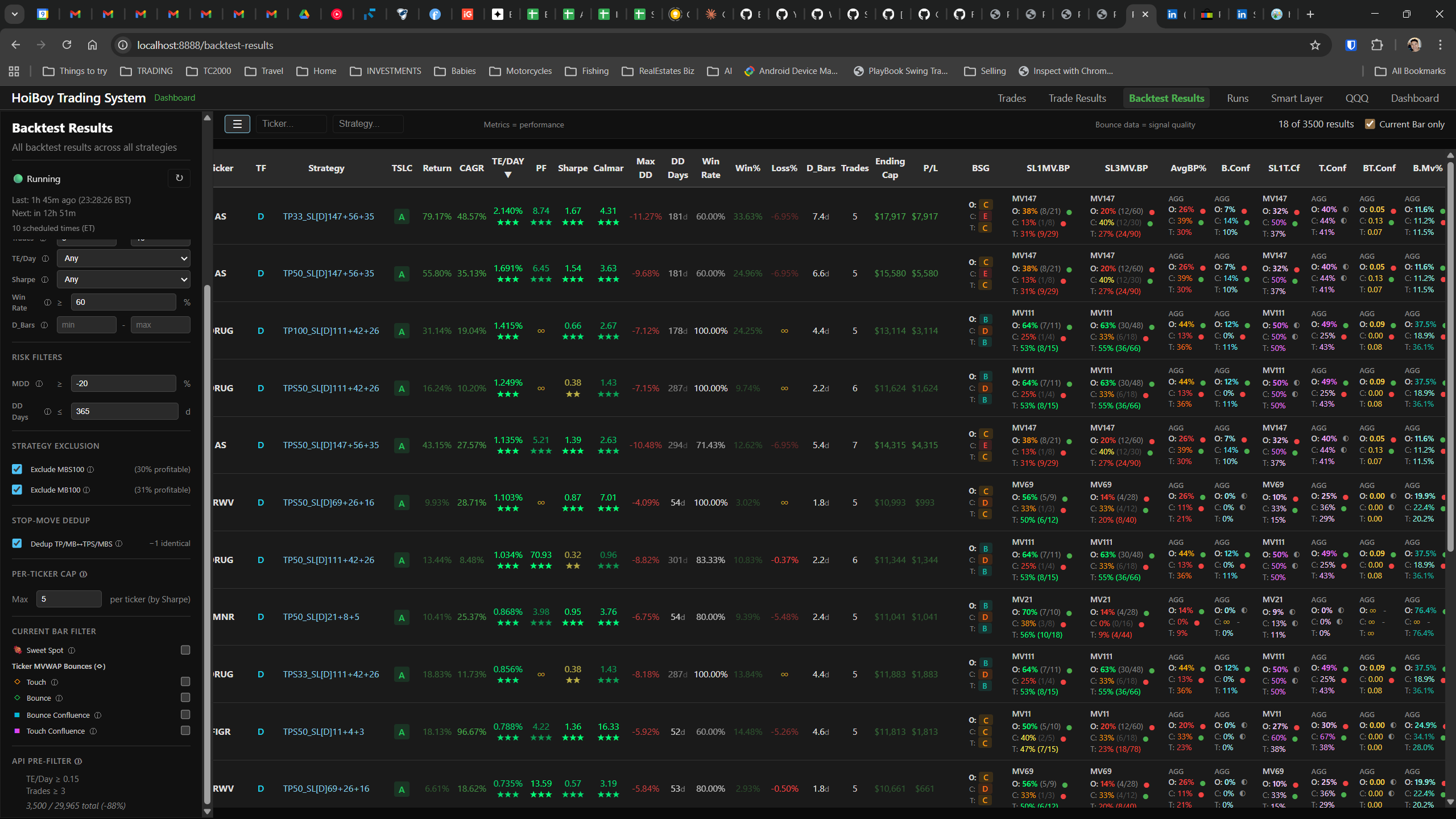
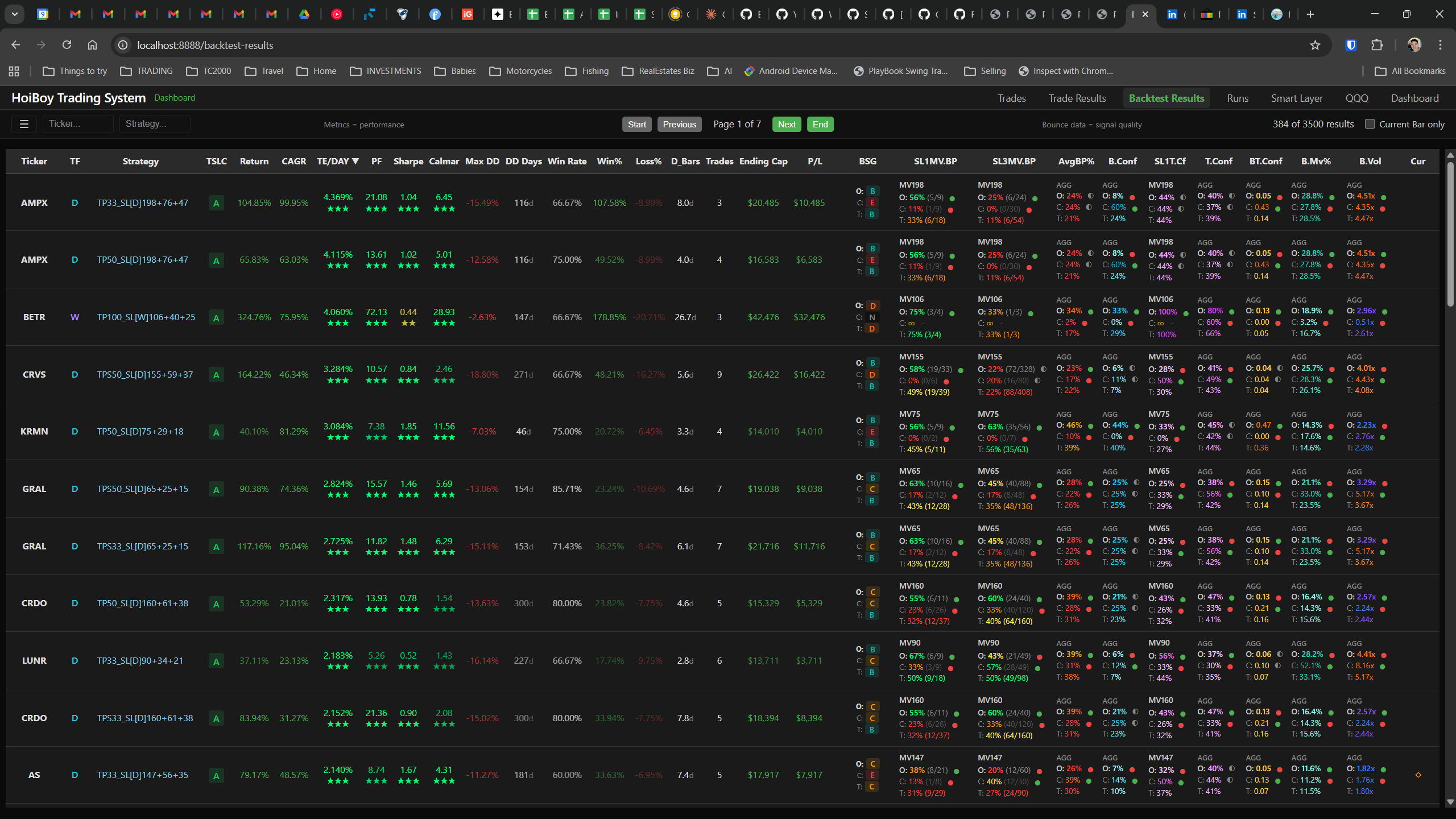
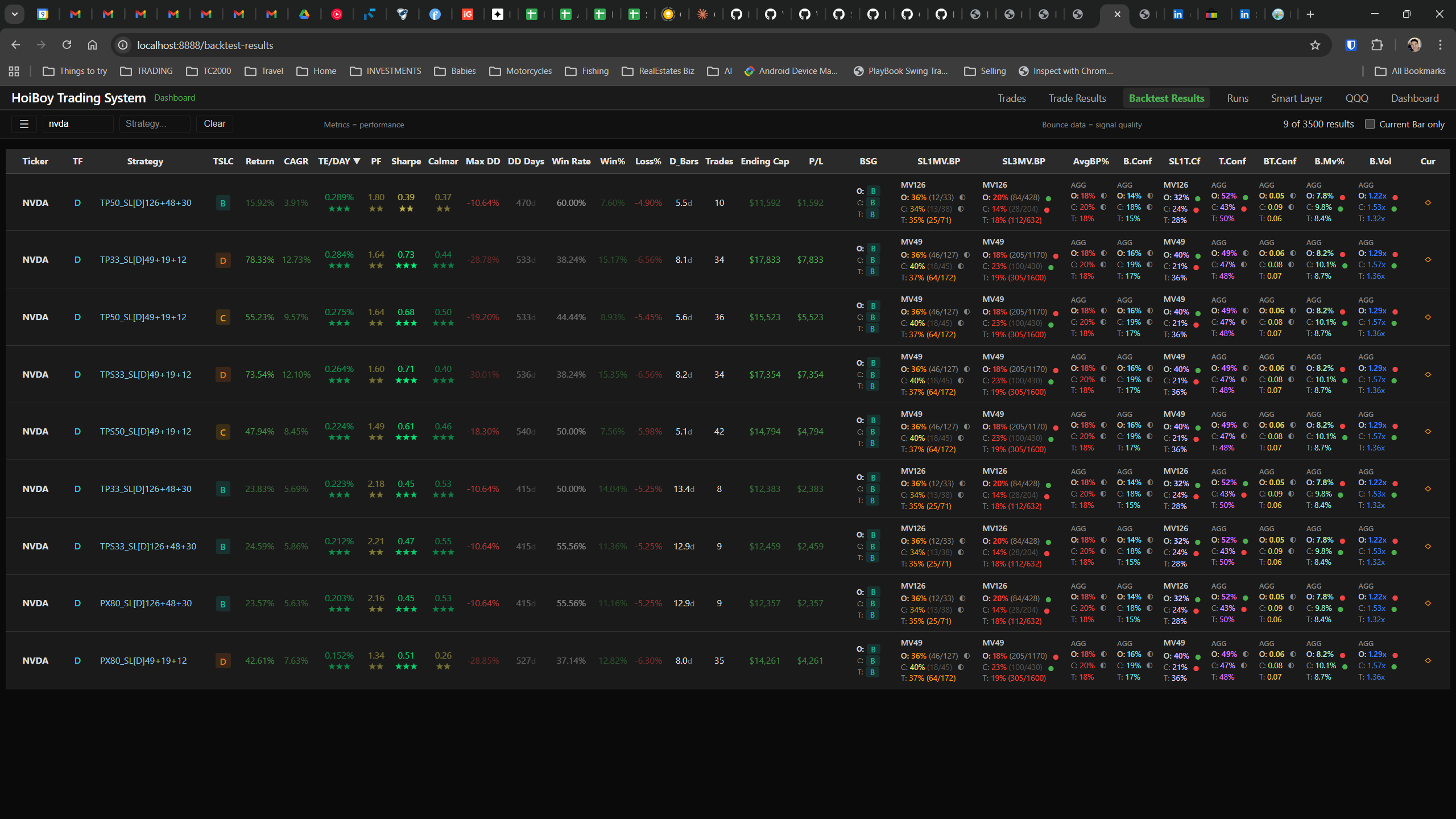
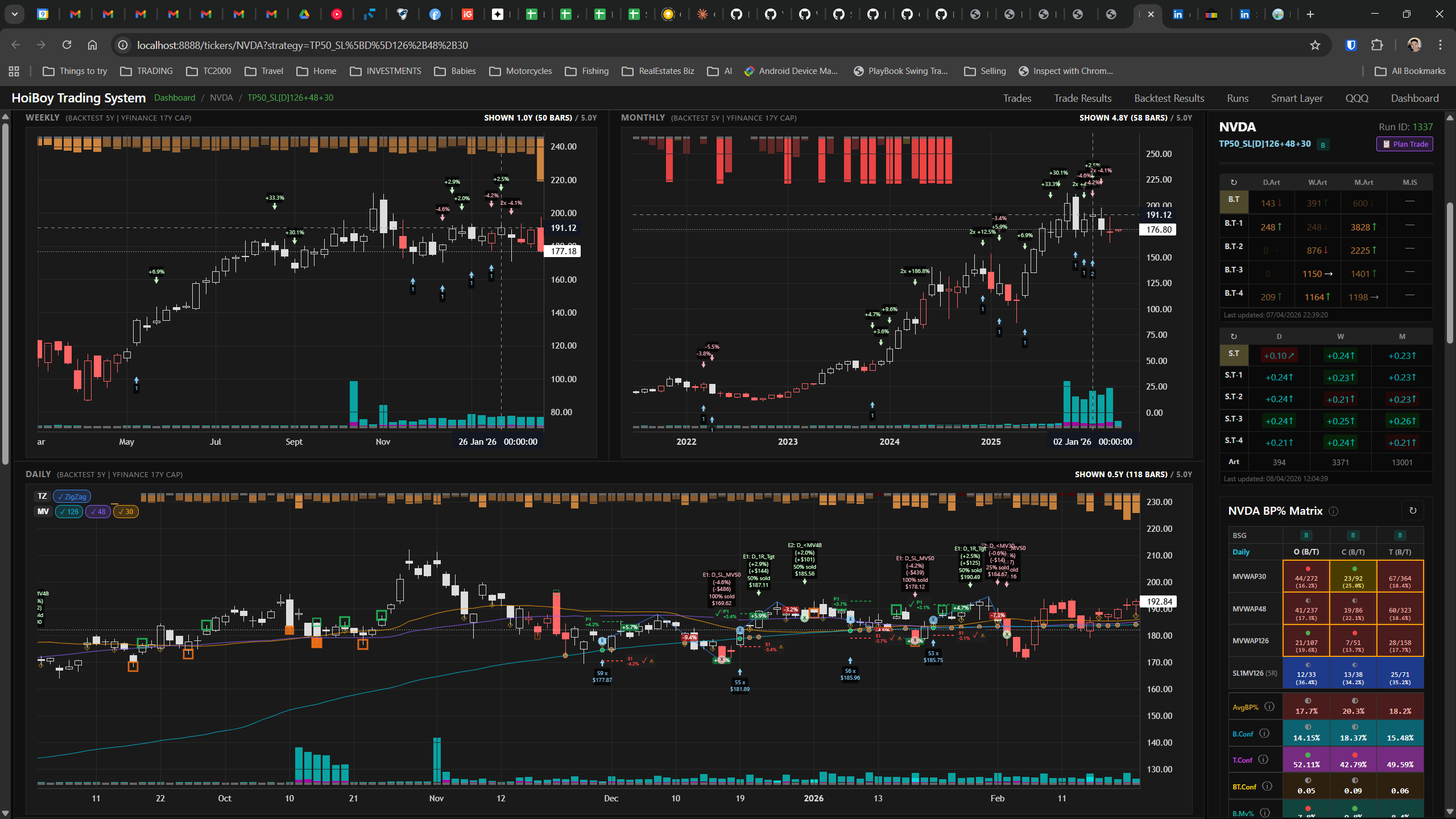
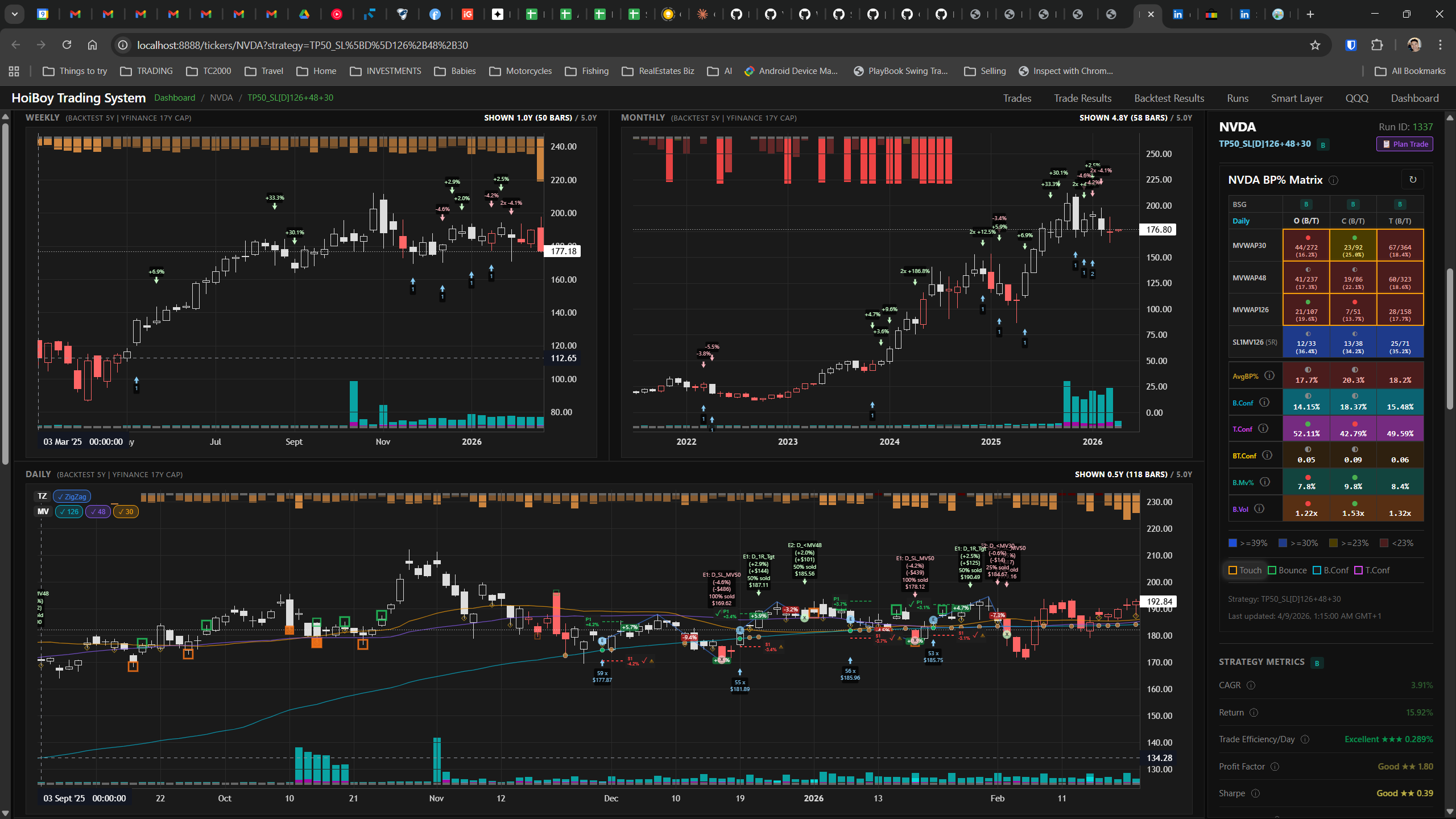
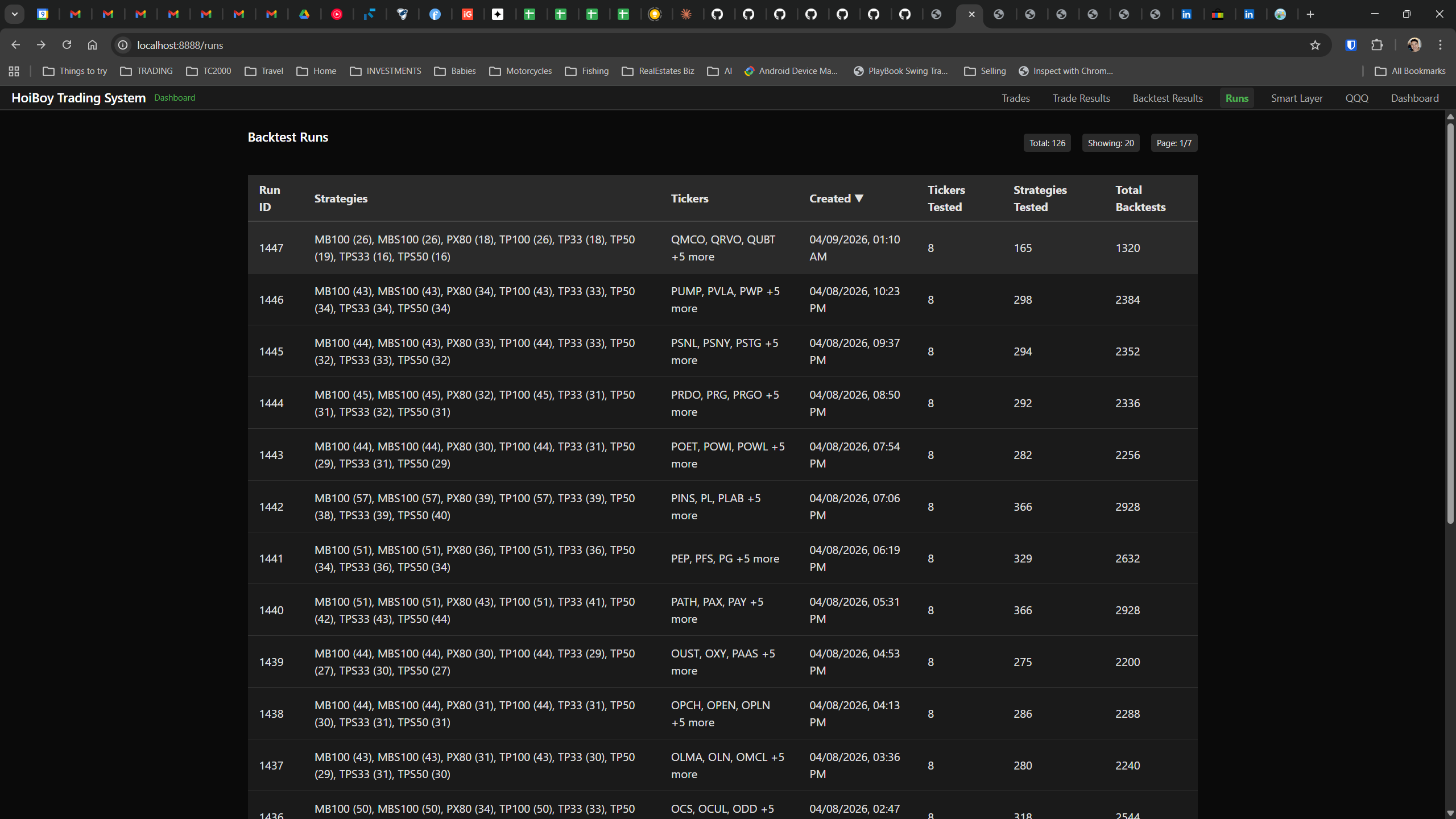
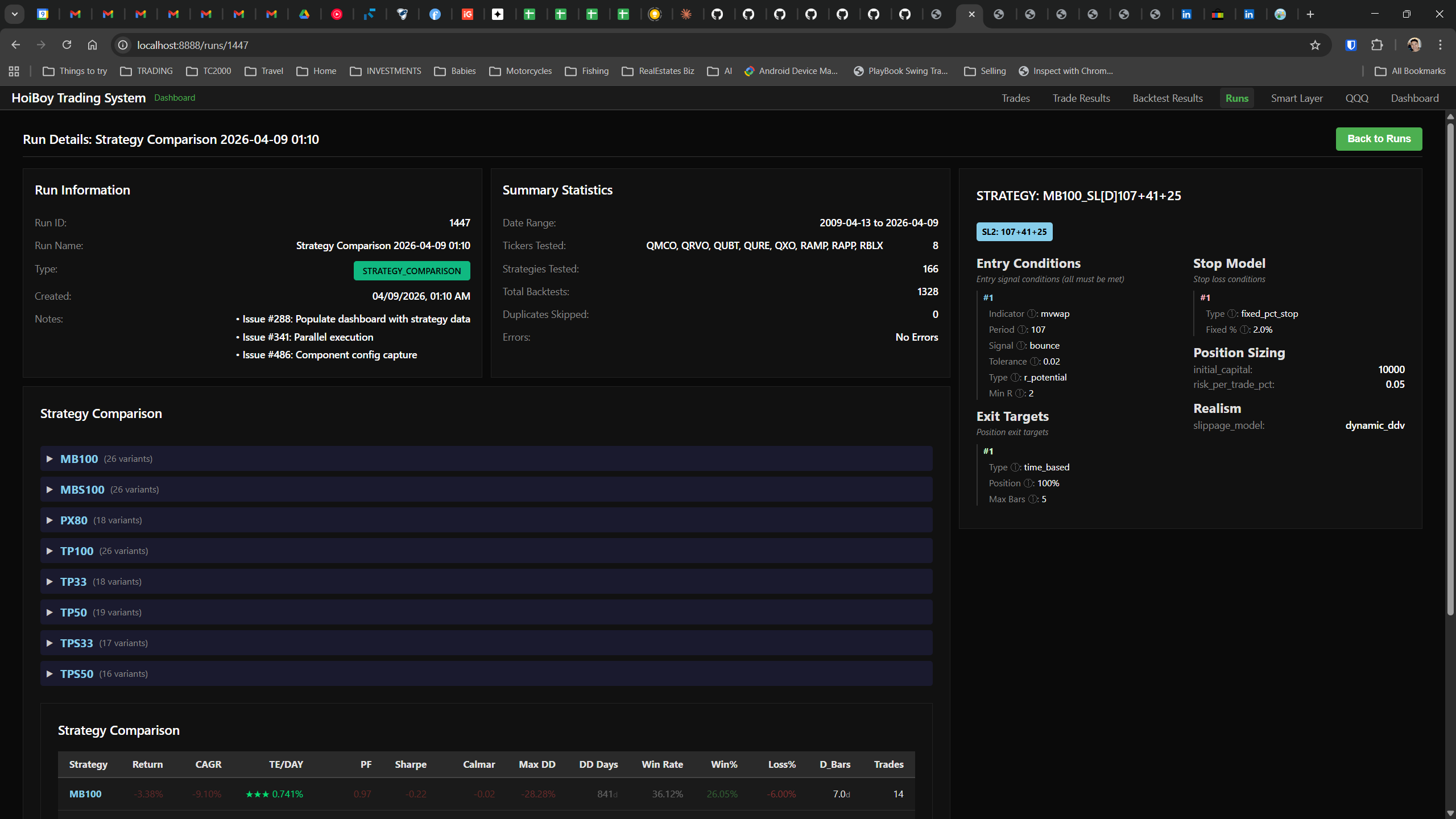
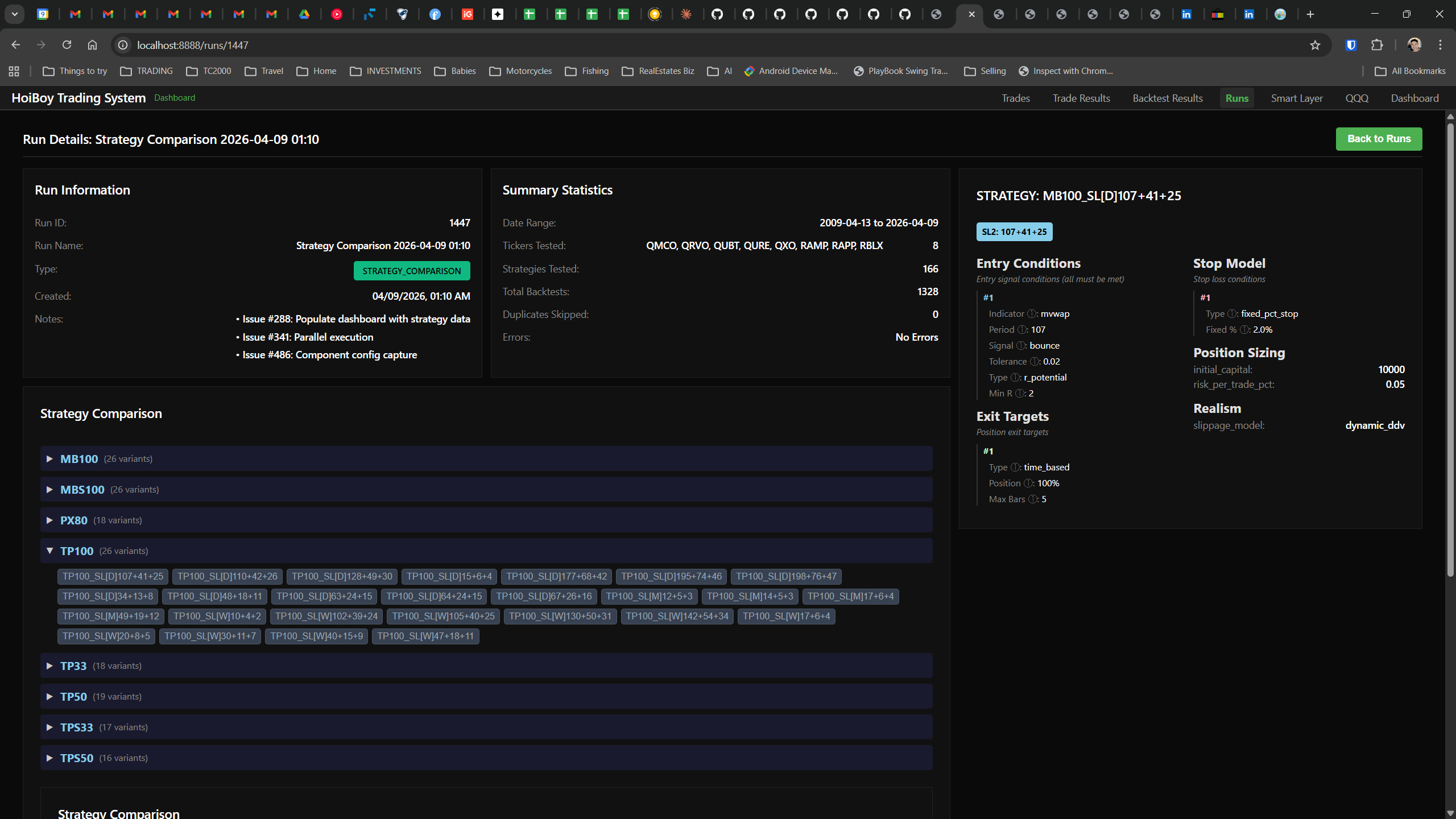
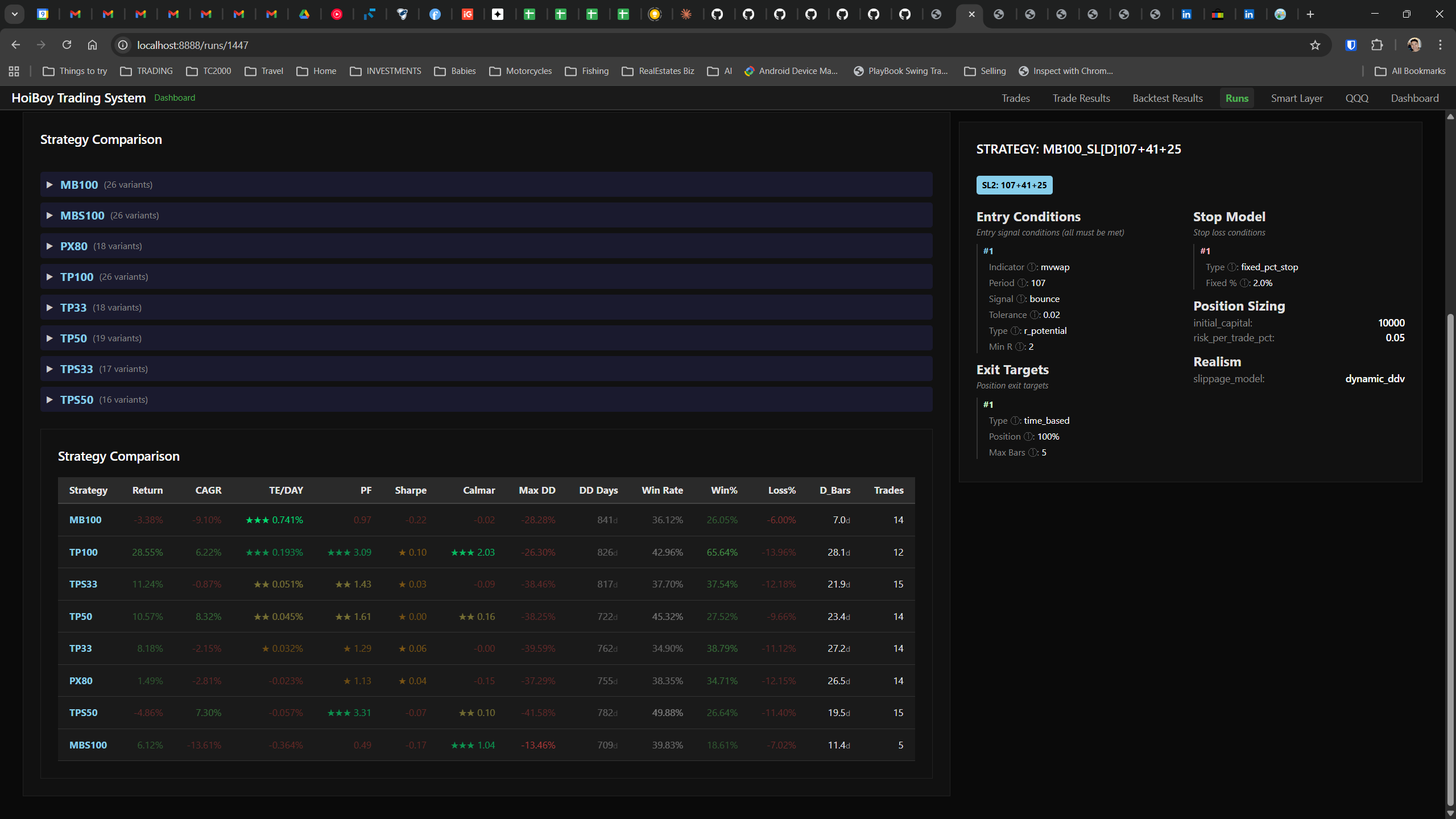
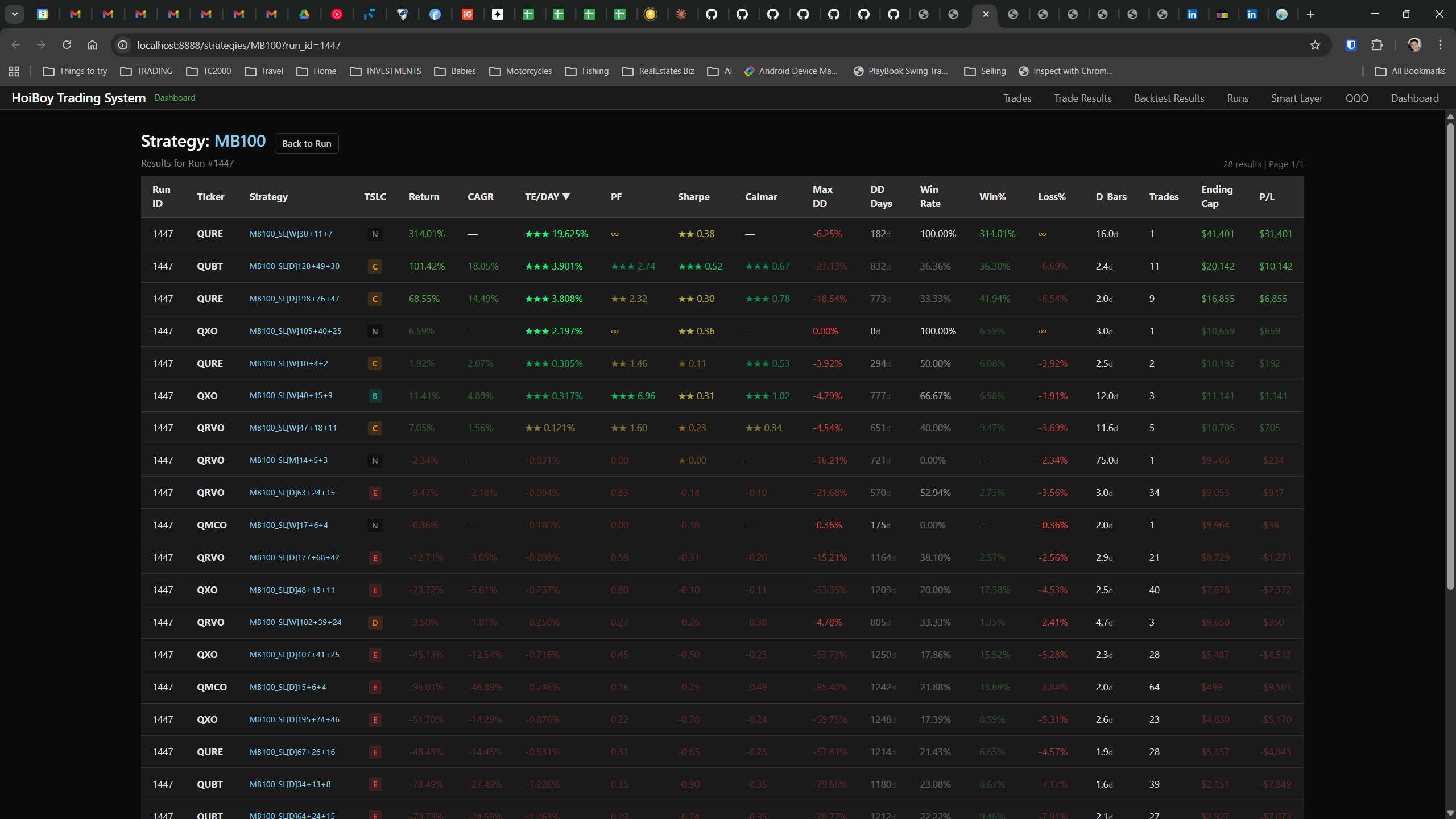
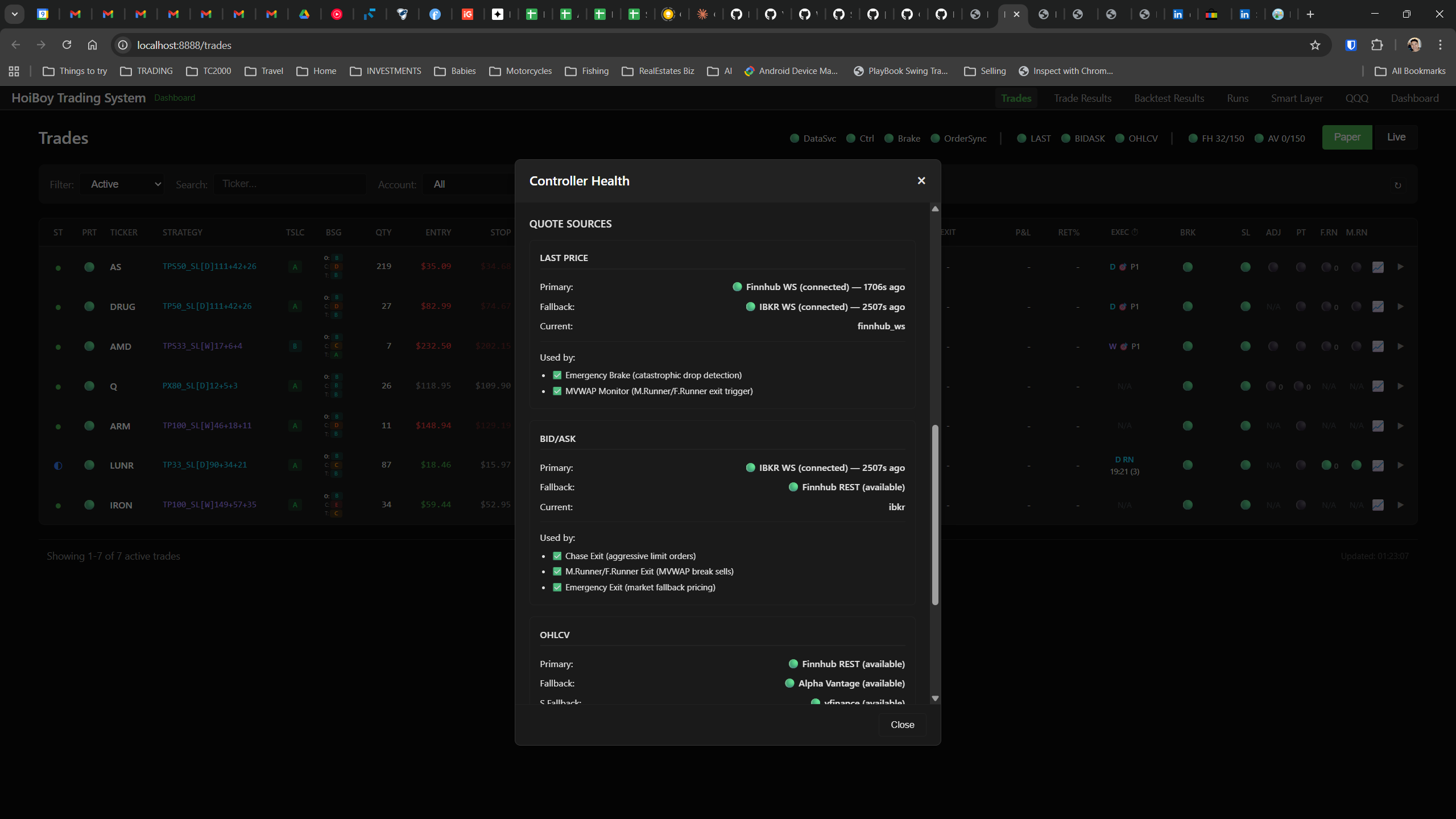
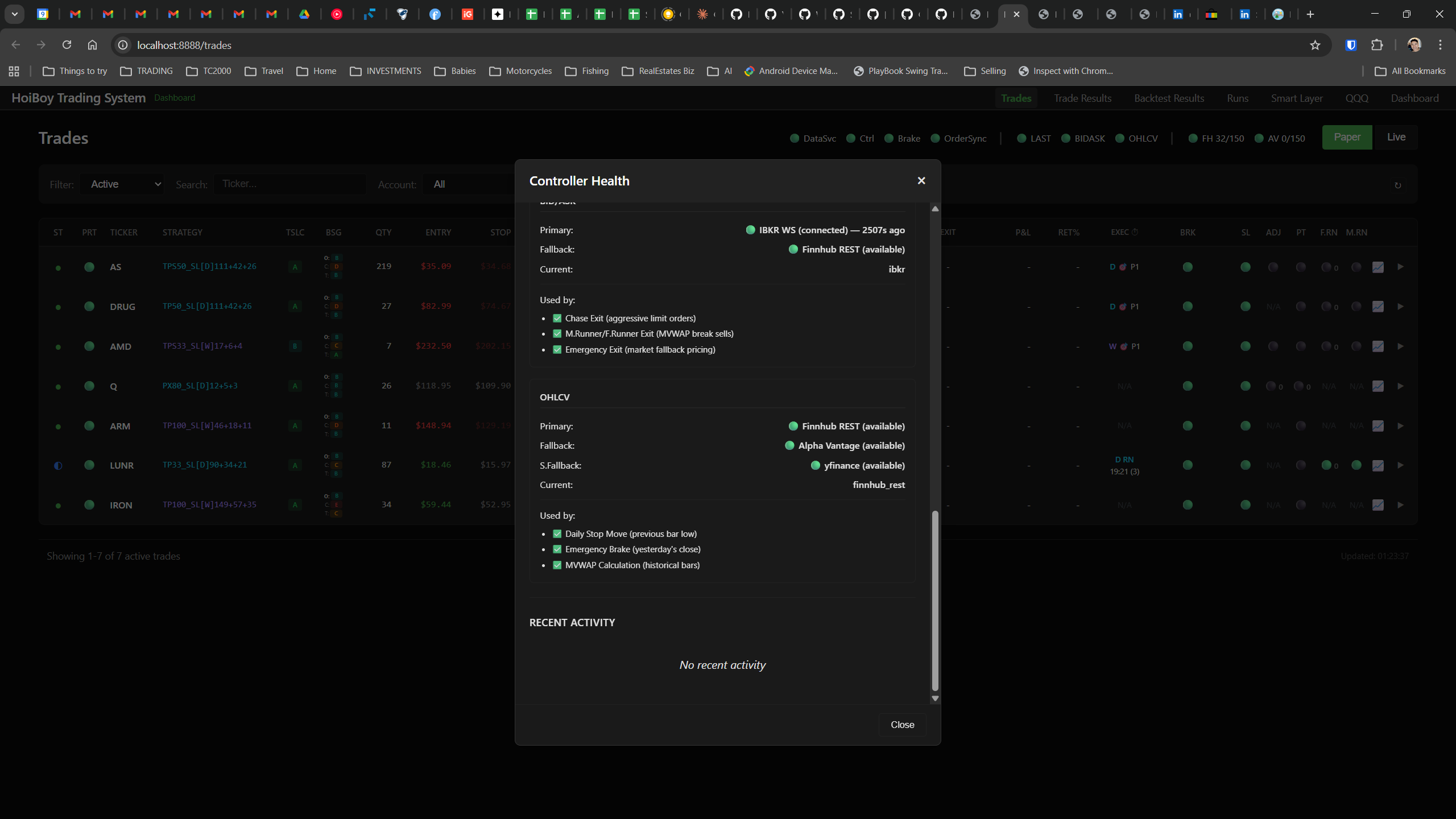
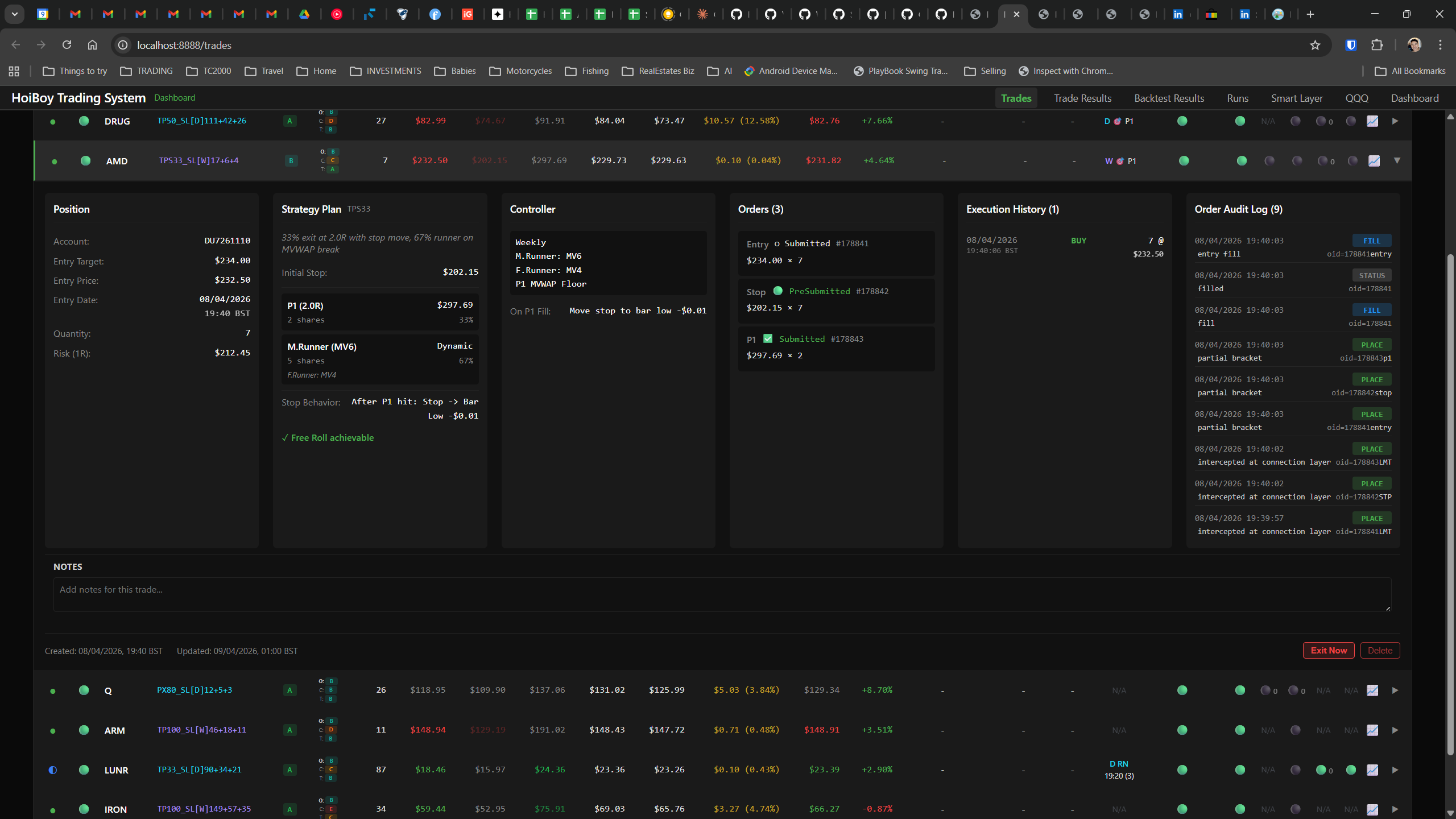
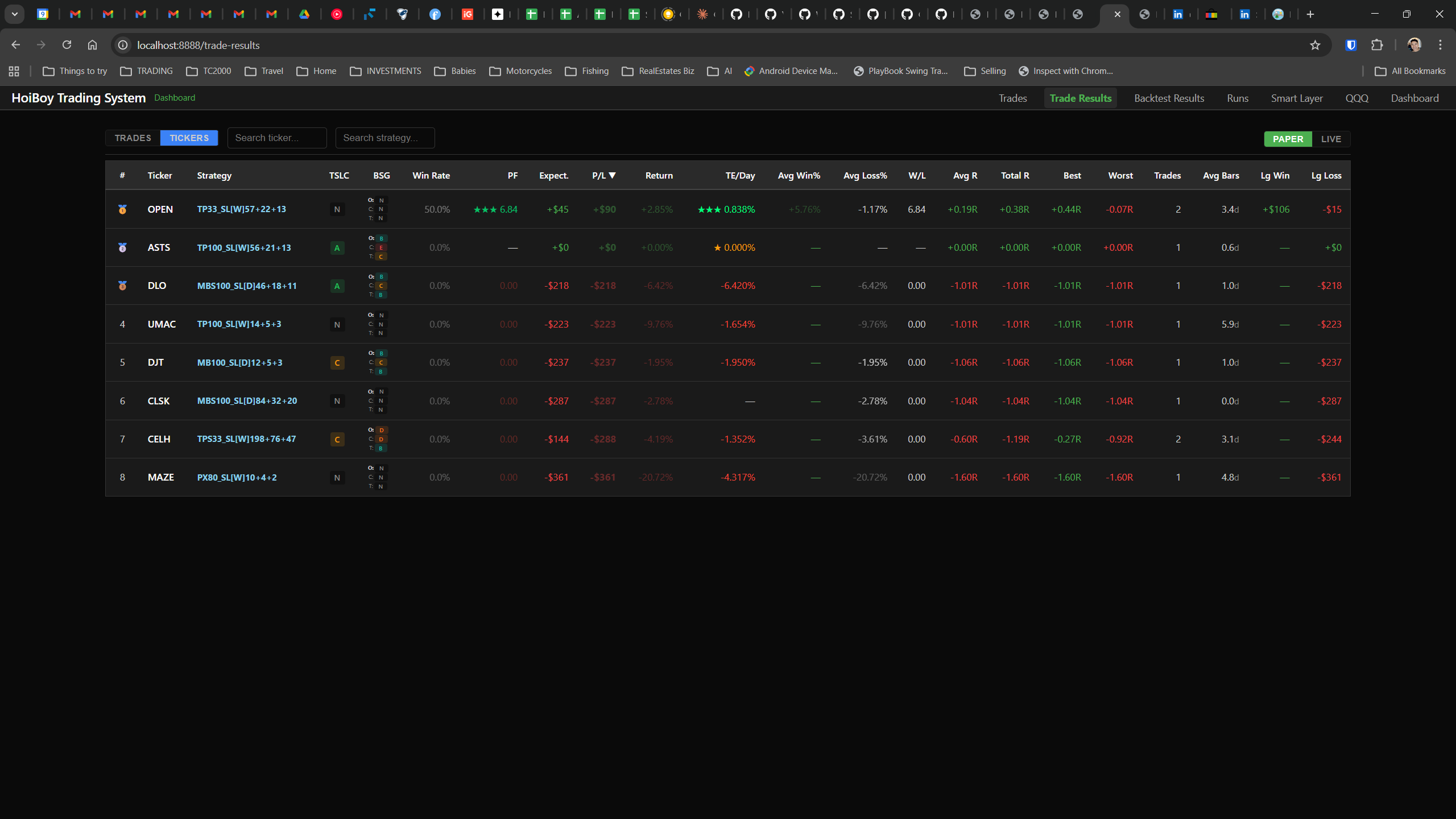
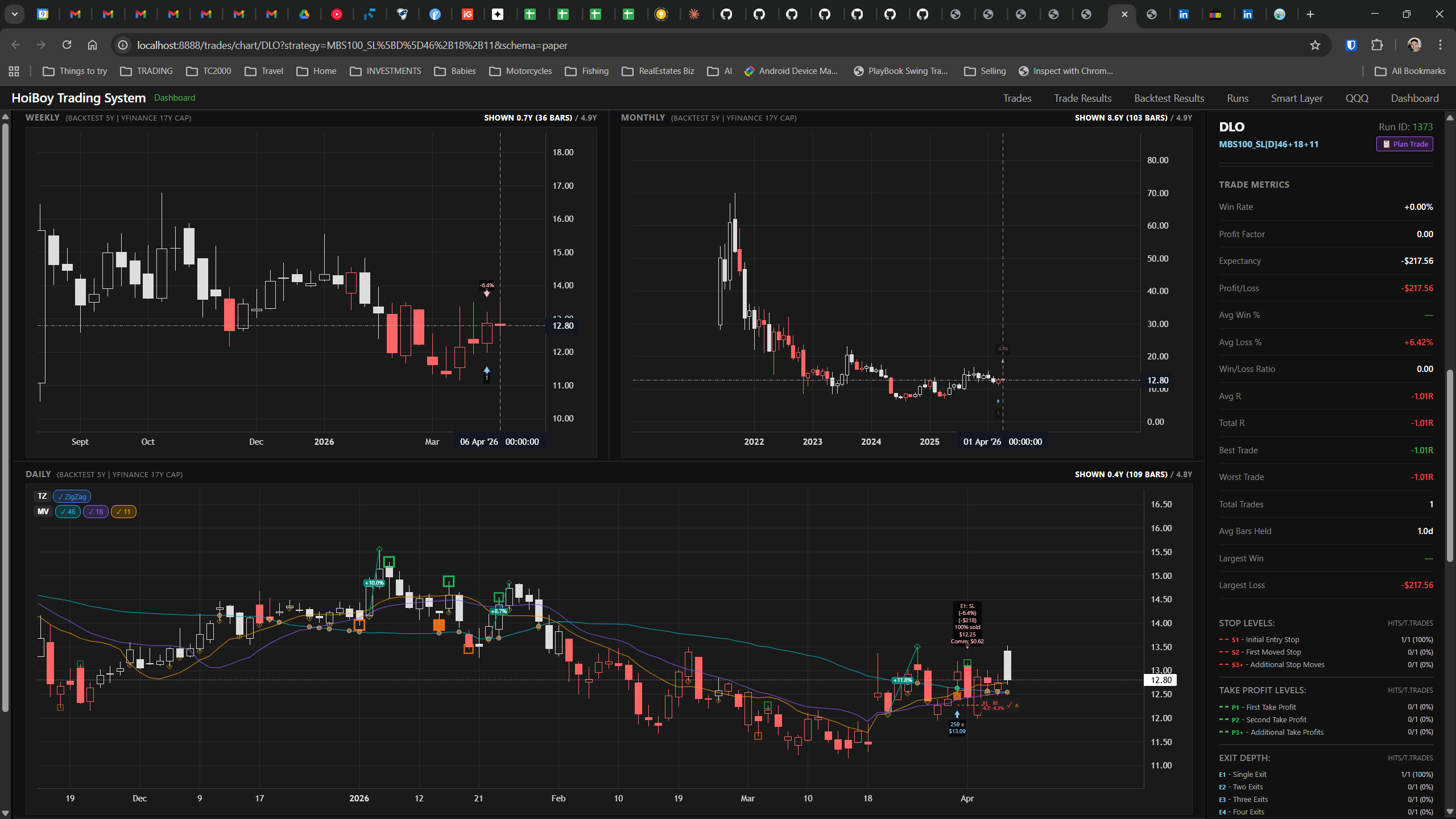
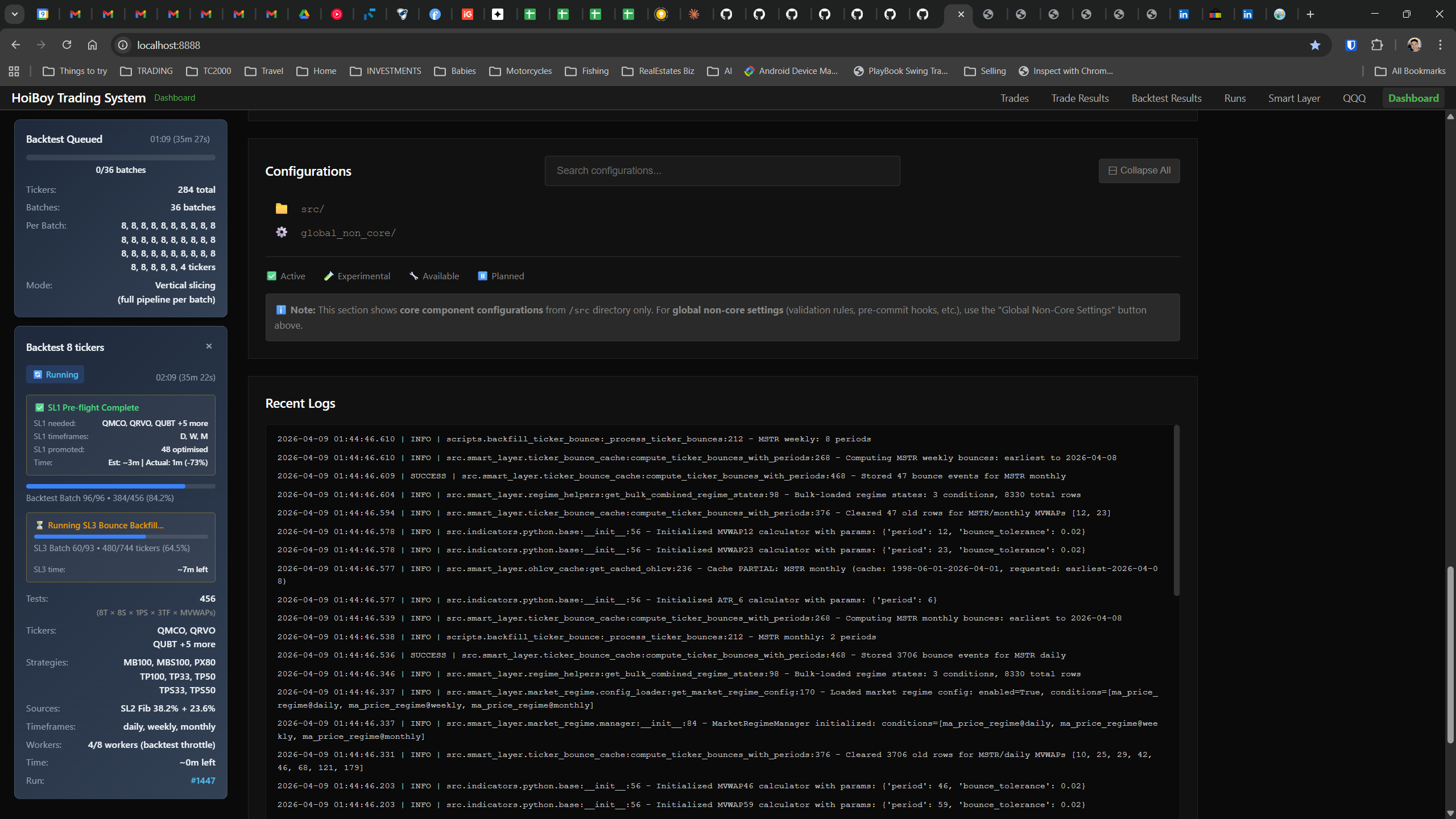
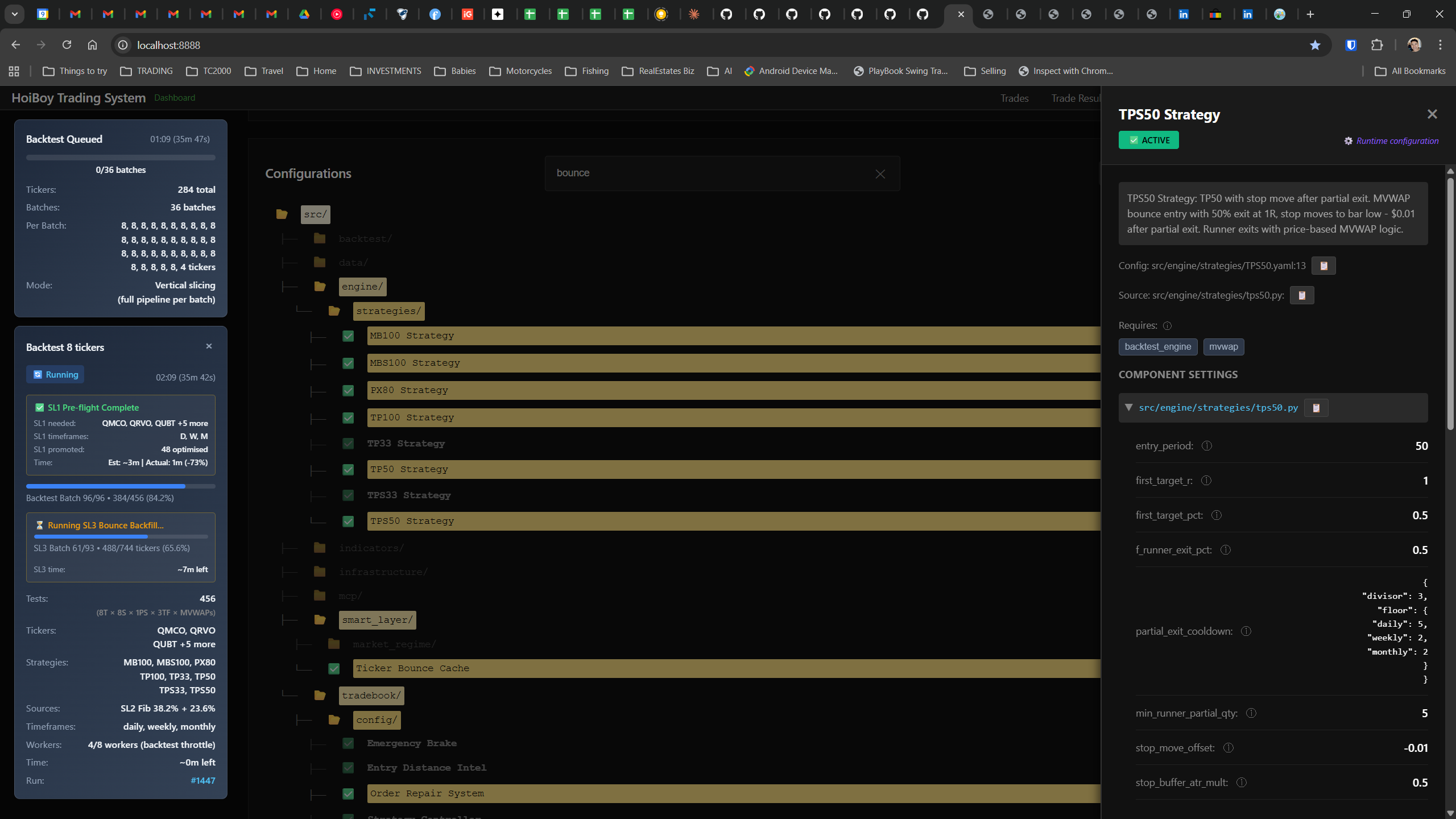
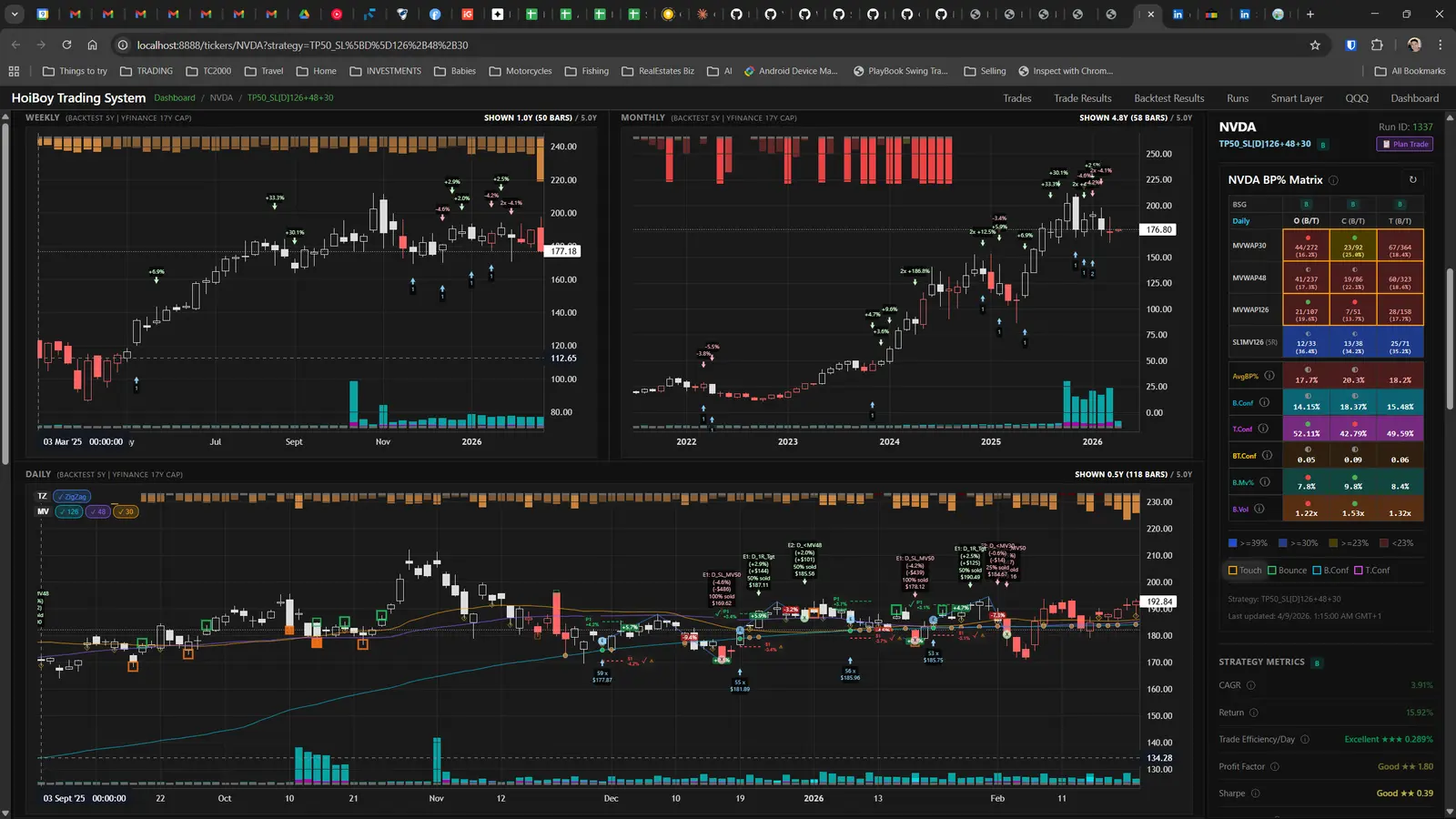
The dashboard home screen showing the backtest engine at rest. An active backtest run crunching through hundreds of tickers. The Smart Layer scanning 744 stocks for bounce signals. NVDA stock detail across three timeframes with MVWAP overlays. The backtest results table (really really dense, I know, but every column earns its place). Cross-strategy comparison for decision-making. Active paper trades being managed in real time. The plan trade screen where I pick entry prices. Order confirmation with safety checks before anything touches the broker. Controller health monitoring showing data service status and emergency brake state. And the trade detail panel showing every order, execution, and audit log entry for a single position.
All of it built with Claude Code. All of it tracked in GitHub issues. All of it running on my local machine managing paper trades against real market data in real time.
What I Actually Learned
Here’s what nobody tells you about building with AI: the building part is kind of easy. Seriously. You describe what you want, the agent writes the code, you review it, you ship it. That bit works.
The tough bit is everything around it. The framework that keeps AI agents in check. The guardrails, the standards, the process, the workflow. Without those? AI probably achieves a 20:80 effectiveness ratio (the polar opposite of what you want). It’ll write code that looks right, passes a quick glance, and breaks in production three weeks later. With the right framework? You flip that to 80:20. You get 80% of your goal done properly, then you refine the next 10-15%, and you’re good. The remaining 5%? That’s usually a waste of time, money, and resources trying to gain very little. Perfection is not a goal. In life, in code, in anything. It’s actually a waste of time and effort. Tech moves so fast that by the time you reach perfection, you’re already legacy and the next big thing is ahead of you. Don’t aim for perfection. Aim for consistency and high quality control. It may not be perfect, but it’s of great value. Know when to stop polishing.
The SST3 workflow is that framework. It matters more than any individual piece of code. I could rewrite the trading system from scratch (and I probably will, parts of it). But the methodology, the quality gates, the anti-patterns, the research-first approach… that’s the thing that compounds.
I’m not a software engineer who uses AI. I’m a product owner and engineering leader who uses AI as the execution layer. I architect the systems, design the methodology, make the technical decisions, manage the quality gates. Claude executes my designs. The engineering mindset and process discipline are my skills. The AI is the force multiplier.
Planning is the hard work. Building is the easy bit. I spent 3 years learning trading before writing code. I spent weeks on research documents before opening an editor. The system has 52 research files in its docs folder. Every major decision has a paper trail. Which backtesting framework? Research doc. Which Rust IBKR library? Research doc. Should we use 3-year, 5-year, or 10-year backtest periods? Research doc. The research told me vectorbt was 10-100x faster than alternatives. It told me the original Rust IBKR library had a connection bug that the Python one didn’t. It told me yfinance was accurate enough for backtesting (I validated it against 161 tickers). None of that would have surfaced by just “building fast and breaking things.”
9,437 commits. 1,419 issues. 136 active days out of 153 (I barely took a day off). 69 days with 12+ hours of work. The longest session was 20 hours straight. Half of it broke. All of it taught me something.
10,000+ commits across 4 repositories. 1,860+ issues with a 99.4% close rate. 11,100+ test cases. The production system will always remain private (it’s my edge and my autonomous trading system). But tradebook_GAS (the spreadsheet MVP) will go public eventually. And this blog? This is built and managed by Claude Code too (commit history and all). Watch this space.
The Full Tour
Every page, every feature. Click through to see what my production-grade trading system looks like under the hood.